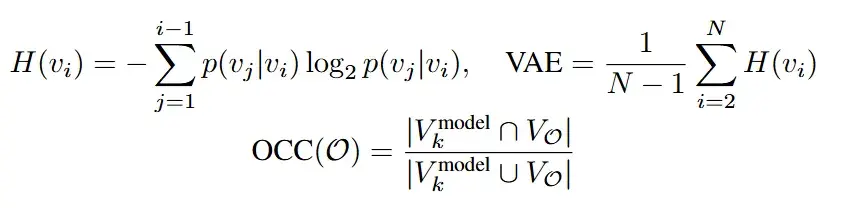大模型推理加速新进展:光明实验室发布 Nüwa,重塑 VLM 空间感知的 Token 裁剪新框架
![]() 发布时间:2026-02-06
发布时间:2026-02-06![]() 作者:光明实验室
作者:光明实验室![]() 浏览:108次
浏览:108次

近日,由光明实验室媒体智能团队马飞研究员主导的大模型Token裁剪工作Nüwa被人工智能领域顶级国际会议ICLR接收(作者:Yihong Huang,Fei Ma,Yihua Shao,Jingcai Guo,Zitong Yu,Laizhong Cui,Qi Tian),其他合作单位还包括西安电子科技大学、香港城市大学、大湾区大学、深圳大学、华为等。
Nüwa: Mending the Spatial Integrity Torn by VLM Token Pruning
Yihong Huang,Fei Ma,Yihua Shao,Jingcai Guo,Zitong Yu,Laizhong Cui,Qi Tian
背景介绍
视觉语言模型(VLMs)虽然在图文理解上表现出色,但其推理由海量视觉Token驱动,计算开销巨大。现有的视觉Token剪枝技术虽然能有效提升推理速度,且在视觉问答(VQA)任务中表现尚可,但在视觉定位(Visual Grounding, VG)任务上却遭遇了严重的性能滑坡。为了探究这一现象,研究团队深入分析了VLM的处理流水线,发现现有的基于全局语义相似度或注意力分数的剪枝策略,往往破坏了由Token位置信息构建的全局空间参考系(Global Spatial Reference Frame)。为了解决这一痛点,提出了Nüwa——一种空间感知的两阶段Token剪枝框架,成功在保持高压缩率的同时,修复了模型的空间感知能力。
核心痛点与研究发现
研究团队通过系统性实验,解决了三个核心问题:
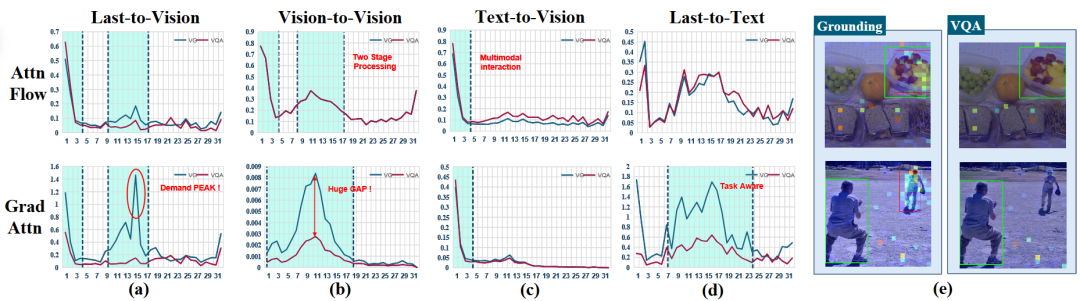
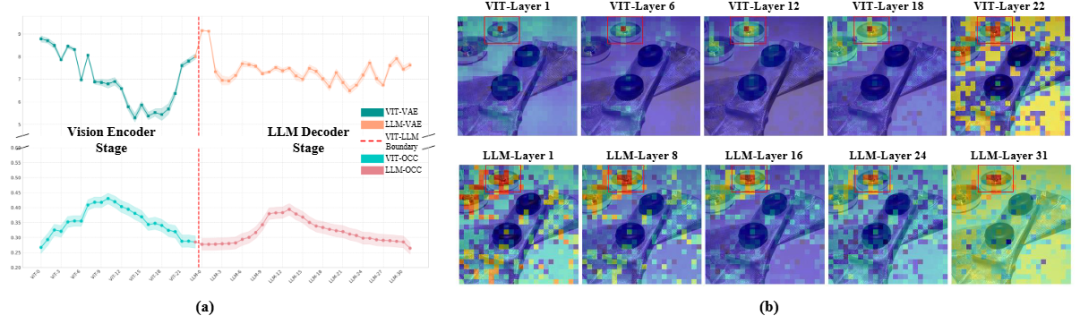
实验表明,VLM的视觉处理在早期阶段具有通用的多模态交互特征,而在中期阶段则根据任务需求(特别是VG任务对视觉信息的高度依赖)表现出显著的分化与适应性。更进一步,研究团队通过两个指标,视觉注意力熵(AVE)和物体中心聚合度(OCC),来揭示了中间层对视觉特征的处理:
最后,研究团队针对现有方法的裁剪机制做了分析,发现他们在中间层之前的裁剪破坏了视觉信息的全局结构特征。因此研究团队通过简单的位置信息重建进行有损修复,一定程度上提升了在定位任务的性能。
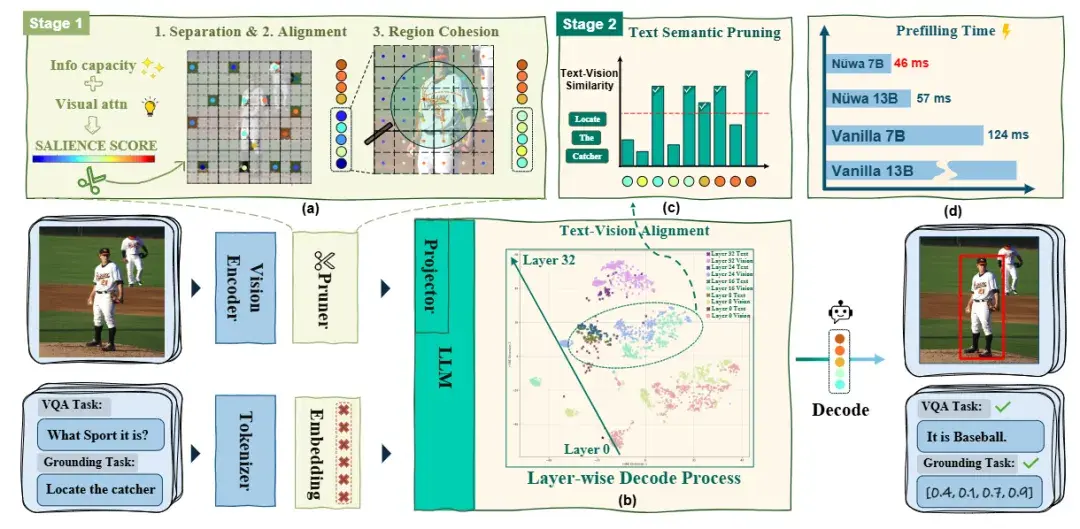
Nüwa 框架
研究团队基于之前的实验分析,开发了Nüwa 框架,其采用了独特的两阶段空间感知剪枝(Two-stage Spatial-aware Token Pruning)策略:
在第一阶段,基于群体智能的空间拓扑保留(Vision Encoder层) 在视觉编码器之后,Nüwa 引入了受 Boids(鸟群/群体智能)算法启发的三大操作:分离(Separation)、对齐(Alignment)、聚合(Aggregation),从而在在视觉语义空间中减少冗余并保持空间拓扑。
在第二阶段,当多模态特征对齐进入大语言模型(LLM)后,Nüwa 利用文本语义信息指导进一步的剪枝,精准保留与任务相关的视觉Token。
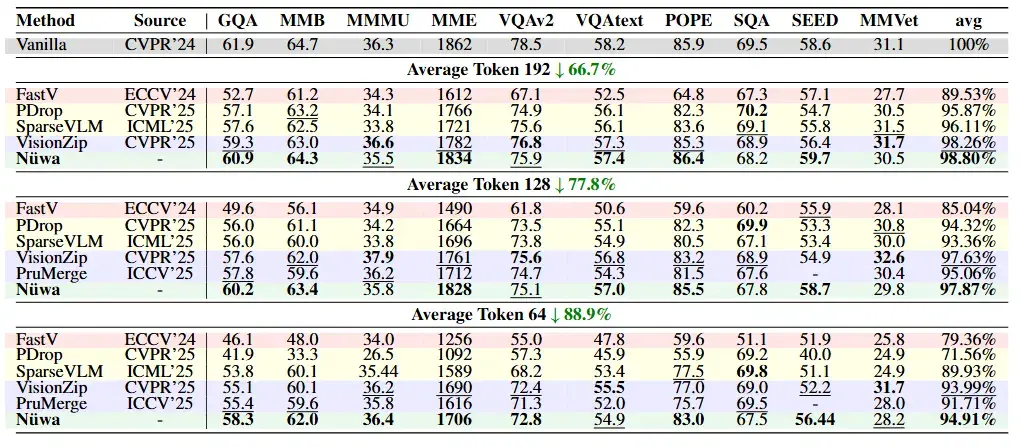
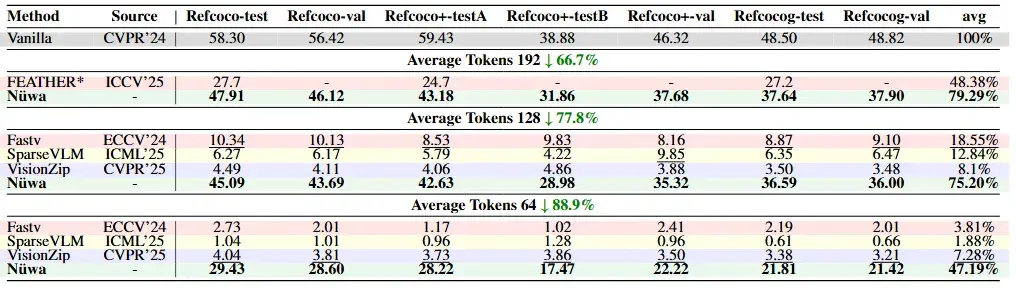
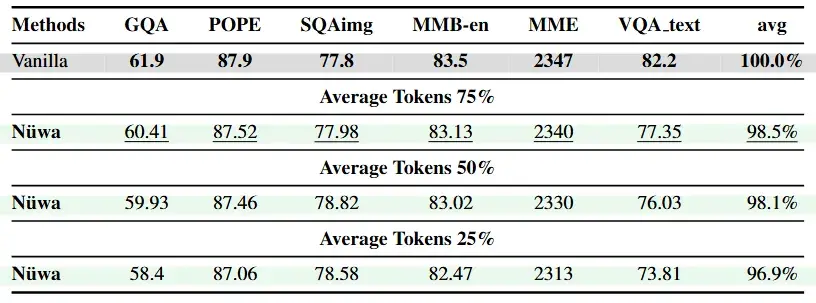
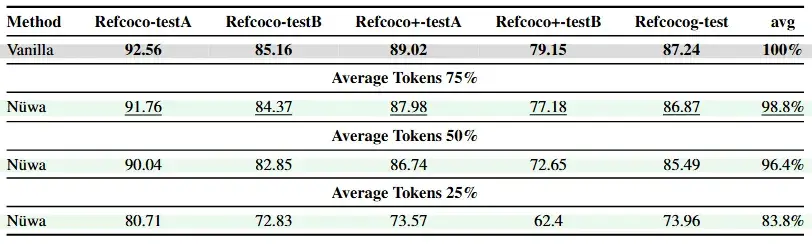
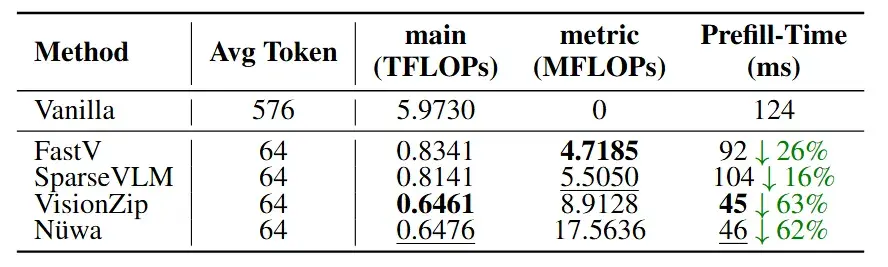
评测结果
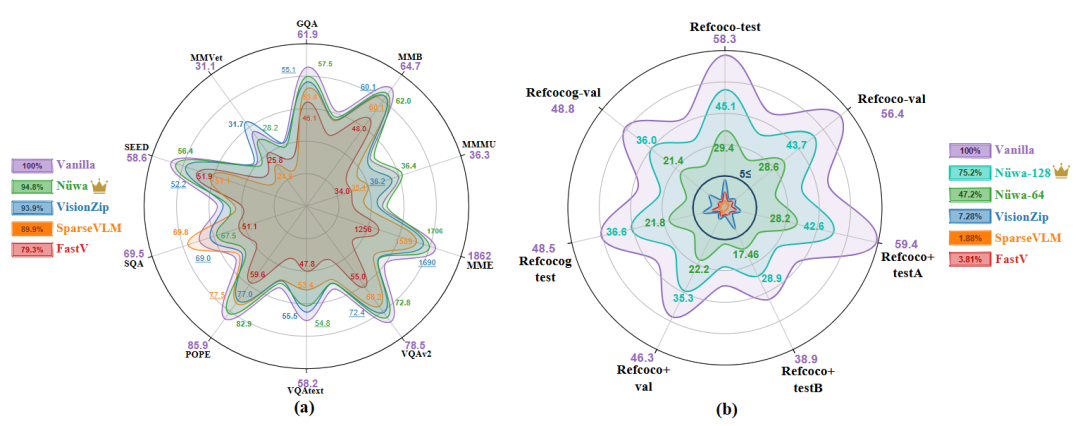
研究团队在LLaVA-1.5、LLaVA-Next、Qwen2.5-VL等多个主流模型上进行了广泛测试,涵盖多个基准数据集。
实验数据表明,Nüwa 取得了令人瞩目的成果:



 发布时间:2026-02-06
发布时间:2026-02-06 作者:光明实验室
作者:光明实验室 浏览:108次
浏览:108次