



大模型规模化联邦调优,光明实验室基础智能团队新突破
![]() 发布时间:2024-09-13
发布时间:2024-09-13![]() 作者:光明实验室
作者:光明实验室![]() 浏览:5937次
浏览:5937次

光明实验室基础智能研究团队最新突破:Ferret: Federated Full-Parameter Tuning at Scale for Large Language Models。作者:Yao Shu(舒瑶), Wenyang Hu, See-Kiong Ng, Bryan Kian Hsiang Low, Fei Richard Yu。
摘要
大语言模型(LLMs)已在众多实际应用中变得不可或缺。然而,在规模化环境下对这些模型进行微调,尤其是在数据隐私和通信效率至关重要的联邦设置中,仍面临着重大挑战。现有方法通常采用参数高效微调(PEFT)来减轻通信开销,但这通常以牺牲模型性能为代价。为解决这些限制,我们提出了大语言模型的规模化联邦全参数调优方法(Ferret),这是首个使用共享随机性的一阶方法,能够在分散数据源之间实现LLMs的可扩展全参数调优,同时保持有竞争力的模型性能。Ferret通过三个方面实现这一目标:(1)采用广泛应用的一阶方法进行高效的本地更新;(2)将这些更新投影到低维空间,大幅减少通信开销;(3)利用共享随机性从这个低维空间重构本地更新,以促进有效的全参数全局聚合,确保快速收敛和具有竞争力的最终性能。我们严谨的理论分析和见解,以及广泛的实验表明,Ferret显著提高了现有联邦全参数调优方法的可扩展性,实现了高计算效率、减少的通信开销和快速收敛,同时保持了有竞争力的模型性能。
概览
近来,大语言模型(LLMs)已成为众多实际应用中不可或缺的工具,从自然语言处理任务如翻译和摘要,到更复杂的任务如代码生成和决策系统。LLMs的巨大规模和多功能性使其在实践中极具价值,但同时也带来了重大挑战,特别是在联邦环境中进行微调时。联邦学习(FL)提供了一种去中心化的方法来微调LLMs,同时将数据保留在本地客户端以确保隐私。然而,虽然这种方法有效地解决了隐私问题,但当LLMs的模型参数规模达到数十亿时,也会导致令人望而却步的通信开销。
减轻LLMs联邦调优中巨大通信成本的一个直接策略是参数高效微调(PEFT)。PEFT方法专注于只微调一部分模型参数,这能显著减少客户端和中央服务器之间的通信开销。尽管在减少带宽使用方面很有效,但这类方法通常会影响模型性能,因为微调一部分模型参数可能无法充分捕捉本地数据分布的细微差别。因此,最近的工作,如FedKSeed,致力于在LLMs的联邦全参数调优中使用零阶优化(ZOO),旨在通过每轮仅在客户端和中央服务器之间传输数千个标量梯度来保持有竞争力的模型性能,同时减少通信开销。不幸的是,与使用一阶优化(FOO)的FL方法(如FedAvg)相比,这种方法常常因其较差的可扩展性而受限,包括每轮增加的计算成本和收敛所需的更多通信轮次。
为此,我们提出了Ferret算法。这是第一个具有共享随机性的一阶FL方法,能够实现LLMs的可扩展联邦全参数调优,同时具有引人注目的计算效率、大幅减少的通信开销和快速的收敛速度,同时保持有竞争力的模型性能。Ferret通过三个方面实现这一目标:首先,它采用广泛应用的一阶方法在每个客户端上执行计算高效的本地更新,与现有的基于ZOO的FL相比,通常需要更少的迭代来实现相同的本地更新过程。其次,Ferret将这些更新投影到低维空间,与现有的基于FOO的FL相比,显著降低了通信成本。最后,Ferret利用共享随机性从低维空间重构本地更新,以进行有效的全参数全局聚合,确保快速收敛和有竞争力的模型性能,相比现有的基于ZOO的FL。具体算法见图 1。我们进一步通过严谨的理论分析和原则性见解来补充Ferret,展示了Ferret相对于其他基线的理论优势,并指导其最佳实践。最后,通过广泛的实验,我们验证了Ferret在可扩展性和模型性能方面显著优于现有方法,使其成为在大规模联邦环境中部署LLMs的理想解决方案。
总结起来,本工作的贡献包括:
✦我们提出了Ferret,这是据我们所知第一个具有共享随机性的一阶FL方法,它显著提高了LLMs联邦全参数调优的可扩展性,同时保持了有竞争力的模型性能。
✦ 我们提出了严谨的理论分析和见解(见论文正文),以支持我们的Ferret的有效性,展示了它相对于其他基线的理论优势,并指导其最佳实践。
✦ 通过广泛的实验,我们证明Ferret在实践中始终优于现有方法,提供了更优的可扩展性和有竞争力的模型性能。

结果
表1展示了Ferret与其他联邦全参数调优算法的理论比较。Ferret作为一种新提出的基于一阶优化(FOO)的方法,在多个方面展现出了显著优势。它保持了FOO方法的计算效率,同时大幅降低了通信开销(从O(d)减少到O(K),与FedKSeed相当)。虽然Ferret比FedAvg需要更多的收敛轮数,但比基于零阶优化(ZOO)的方法如FedZO和FedKSeed要少得多。此外,Ferret在适应性、泛化能力和隐私保护等方面都表现出色,尤其是在隐私保护方面与FedKSeed并列最佳。这种在计算效率、通信开销、收敛速度以及其他关键因素之间的最佳平衡,使Ferret成为一个高度可扩展且理想的解决方案,特别适用于大语言模型(LLMs)的联邦全参数调优。它有效地解决了之前方法面临的挑战,如过高的通信开销、模型性能损失和较差的可扩展性等问题,为LLMs在大规模联邦环境中的部署提供了一个强有力的工具。
表2详细比较了不同联邦全参数调优算法在LLaMA-3B模型上的计算成本和通信开销。总体而言,Ferret算法在多个方面展现出了显著的性能优势。在计算成本方面,Ferret的本地更新时间(5.6秒)比FedKSeed快4.4倍,全局聚合时间(49.1秒)比FedKSeed快14.7倍,总体计算时间(6.6×10²秒)比FedKSeed快45.5倍。在通信成本方面,Ferret每轮的通信量(7.8×10³参数)以及总体通信量(9.4×10⁴参数)均比比FedAvg少10⁶倍。这些数据清晰地表明,Ferret在计算效率和通信效率上都实现了显著的改进,特别是相比于FedKSeed在计算成本上的优势,以及相比于FedAvg在通信成本上的巨大节省。这种全面的性能提升使Ferret成为大规模语言模型联邦学习中一个非常有竞争力的解决方案,能够有效地平衡计算资源利用和网络带宽消耗,为实际应用中的大语言模型调优提供了更高效的方法。
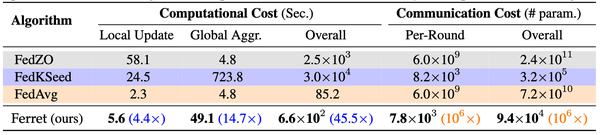
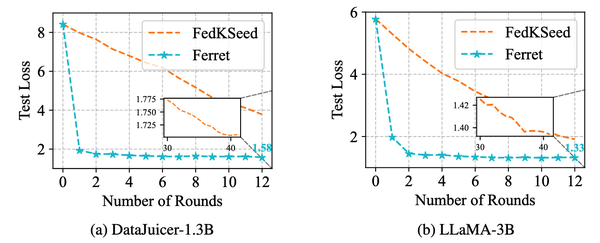
图2展示了在Natural Instructions任务上,Ferret与FedKSeed两种算法在DataJuicer-1.3B和LLaMA-3B模型上所需的通信轮数对比。从图中可以看出,Ferret(蓝色实线)展现了显著的收敛速度,仅需大约2轮通信即可达到较低的测试损失,而FedKSeed(橙色虚线)则需要超过12轮才能接近相似的收敛效果。放大的区域进一步展示了FedKSeed在收敛速度上的劣势。这表明Ferret在通信轮数复杂度上实现了接近20倍的加速,极大地提高了通信效率。
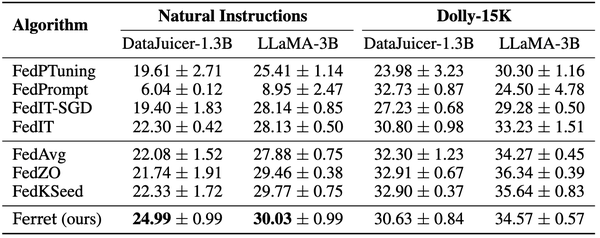
最后,表3比较了Ferret与其他联邦全参数调优算法在两个任务(Natural Instructions和Dolly-15K)和两个模型(DataJuicer-1.3B和LLaMA-3B)上的Rouge-L评分表现。Ferret算法在大多数情况下展现出了优秀的性能。在Natural Instructions任务中,Ferret在DataJuicer-1.3B模型上获得了最高分(24.99 ± 0.99),在LLaMA-3B模型上也取得了很好的成绩(30.03 ± 0.99)。在Dolly-15K任务上,Ferret在DataJuicer-1.3B模型上的表现(30.63 ± 0.84)虽然不是最佳,但仍然优于许多其他算法;在LLaMA-3B模型上,Ferret获得了34.57 ± 0.57的分数,接近最高分。值得注意的是,Ferret在大多数情况下都表现出较小的标准差,这表明其结果的稳定性和可靠性。总的来说,这些结果表明Ferret算法在不同任务和模型上都能够保持竞争力,展现出了良好的泛化性和稳定性。
总结
总之,Ferret算法为联邦环境下的大语言模型(LLMs)提供了一个高效且可扩展的全参数调优解决方案。通过实现高计算效率、快速收敛和降低通信开销,Ferret克服了现有方法的局限性,在这些关键因素之间达到了更好的平衡。此外,我们的严格理论分析和大量实验验证了Ferret作为一种稳健且可靠的方法,能够在大规模联邦学习场景中高效部署LLMs。
原文
Yao Shu, Wenyang Hu, See-Kiong Ng, Bryan Kian Hsiang Low, Fei Richard Yu. Ferret: Federated Full-Parameter Tuning at Scale for Large Language Models. arXiv:2409.06277.
参考文献
[1] Zhen Qin, Daoyuan Chen, Bingchen Qian, Bolin Ding, Yaliang Li, and Shuiguang Deng. Federated full-parameter tuning of billion-sized language models with communication cost under 18 kilobytes. In Proc. ICML, 2024.
[2] Wenzhi Fang, Ziyi Yu, Yuning Jiang, Yuanming Shi, Colin N. Jones, and Yong Zhou. Communication-efficient stochastic zeroth-order optimization for federated learning. IEEE Trans. Signal Process., 70:5058–5073, 2022.
[3] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Proc. AISTATS, 2017.
[4] Yao Shu, Xiaoqiang Lin, Zhongxiang Dai, and Bryan Kian Hsiang Low. Heterogeneous federated zeroth-order optimization using gradient surrogates. In ICML 2024 Workshop on Differentiable Almost Everything: Differentiable Relaxations, Algorithms, Operators, and Simulators, 2024.
END
素材来源 丨光明实验室基础智能研究团队
编 辑 丨 李沛昱
审 核 丨 郭 锴



 发布时间:2024-09-13
发布时间:2024-09-13 作者:光明实验室
作者:光明实验室 浏览:5937次
浏览:5937次