



科研动态 | 光明实验室于非院士与紫金山实验室刘韵洁院士团队:基于量化智能的强化学习在Web3车联网中应用
![]() 发布时间:2023-09-22
发布时间:2023-09-22![]() 作者:光明实验室
作者:光明实验室![]() 浏览:4822次
浏览:4822次

光明实验室于非院士团队与紫金山实验室刘韵洁院士团队合作,提交的一篇基于量化智能的强化学习在Web3车联网中应用的文章Connected and Autonomous Vehicles in Web3: An Intelligence-based Reinforcement Learning Approach(作者:任语铮、谢人超、于非、张然、王宇航、贺颖、黄韬、刘韵杰)被中科院1区、智能交通领域顶级期刊IEEE Transactions on Intelligent Transportation Systems (IEEE TITS) 接收。
摘要
如何量化智能是人工智能领域重要的科学问题之一。在本文中,我们根据智能的定义,推导出量化智能的模型,提出了一种基于智能的强化学习(Intelligence-based RL,IRL)方法,给出了基于量化智能的问题描述方式。该方法使用户可以建立对环境的更高层次的认知,并可以通过选择那些能为他们带来偏好的期望状态分布的动作来直接达到首选状态,避免因定义奖励函数天然存在的泛化性差、准确表征难等问题,从而克服传统强化学习方法的固有局限。结果表明,所提IRL 方法不仅在没有奖励的模型交易问题上优于基准,而且还保持了探索和利用之间的自动平衡。另外,本文把该算法用到Web3车联网系统中,很大的提高了系统的性能。
主要内容
作为以用户为中心的新一代万维网,Web3通过构建新的基础设施、共识机制与智能合约等赋予网络新的能力,让用户控制其数字身份和资产所有权。在Web3中,车辆用户能够去中心化地交易人工智能 (Artificial Intelligence,AI) 模型,以支持自动决策、增强驾驶安全性并减少污染。模型交易策略对车辆用户至关重要,其中强化学习(Reinforcement Learning,RL)作为主流方案,已经取得了许多令人瞩目的成果。
然而,目前主流的强化学习范式,需要寻找有利于最大化累积奖励总和的策略,其成功与否在很大程度上依赖于用户偏好表征与奖励函数的形式,这将严重挑战这些策略的可行性和泛化能力,从而阻碍上述方法的进一步使用。首先,在部分环境下。很难为强化学习定义一个明确和适当的奖励函数。由于人类认知偏差等原因,人类知识向数字奖励值的转化往往是不完善的,而不完美的奖励通常会导致智能体收敛到次优策略甚至不收敛。其次,智能体通常在不同的环境中驾驶,具有不同的硬件设备和偏好,导致匹配不同的奖励函数。因此,在一种环境下训练的策略很难应用于另一种环境。
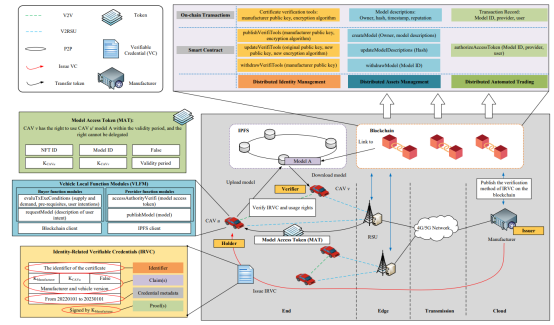
因此,为解决上述问题,我们提出了一种基于量化智能的强化学习(Intelligence-based RL,IRL)方法。 图1为所提系统架构,其大致可以分为三个主要部分。第一,灰色部分给出了实际部署架构,车辆用户与RSU建立通信并连接到互联网。从逻辑上讲,车辆用户形成 IPFS 网络,RSU和制造商维护区块链网络。第二,图1上半部分说明了区块链支持的三大功能:分布式身份管理、分布式资产管理和分布式自动交易。以及为了实现上述功能,需要存储在区块链上的元数据格式和定义的智能合约。第三,图1左侧展示了部署在车辆上的功能模块以及交互的数据格式,以便支持分布式身份管理、分布式资产管理和分布式自动交易三个主要功能。
基于上述框架,我们对模型交易策略进行建模,制定了以下联合优化问题,如图2所示:
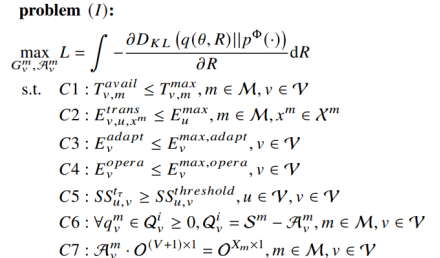
该问题的目标是智能体通过调整动作来提升其智能水平L。其中,智能是一种更高层次的指标,衡量学习过程中随着时间的推移传播了多少信息,或者与之前的状态相比,学习发生后信息传播的范围有多大。在该方程中,车辆用户的真实偏好是未知的,无法被明确表达,只能由约束部分地表示。智能体可以通过选择可以给他们带来期望分布的状态的动作,直接达到首选状态来获得偏好,并根据外部环境输入的新信息不断调整其对外部环境的内部信念,形成对环境的更高层次的认知。
图3给出了所提IRL算法的主要流程。图3的左侧是具有隐藏状态的真实环境,图3的右侧是智能体对真实环境的推断。在真实环境中,车辆用户存储和交易模型,导致延迟和消耗能量。每个车辆用户都有自己的偏好,由有偏生成式模型表示。在推理中,智能体根据观测形成对未来的信念。通过学习,智能体将最小化预期的自由能,从而使对未来的信念逐渐趋向于真实环境。在学习中,智能体以智能为指标来寻求策略。
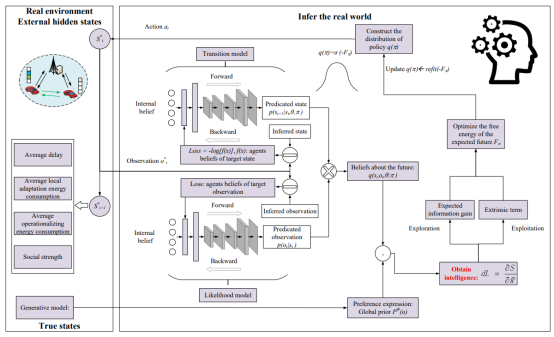
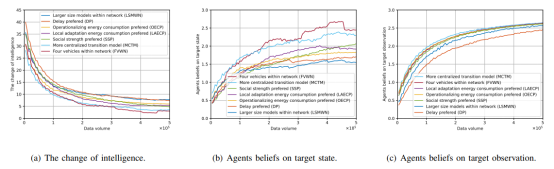
图4为所提方案在不同环境下的实验结果。可以看出随着训练的进行,该方案使得智能体的智能水平上升,对外部环境的信念增强。
原文:Yuzheng Ren, Renchao Xie, F. Richard Yu, Ran Zhang, Yuhang Wang, Ying He, Tao Huang, and Y. Liu. Connected and Autonomous Vehicles in Web3: An Intelligence-based Reinforcement Learning Approach, IEEE Transactions on Intelligent Transportation Systems, accepted, Sept. 2023.
参考文献
Reference
[1] C. Chen, L. Zhang, Y. Li, T. Liao, S. Zhao, Z. Zheng, H. Huang, and J. Wu, “When digital economy meets Web3.0: Applications and challenges,” IEEE Open Journal of the Computer Society, vol. 3, pp. 233–245, 2022.
[2] Y. Hu, W. Wang, H. Jia, Y. Wang, Y. Chen, J. Hao, F. Wu, and C. Fan, “Learning to utilize shaping rewards: A new approach of reward shaping,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), 2020.
[3] O. Avellaneda, A. Bachmann, A. Barbir, J. Brenan, P. Dingle, K. H. Duffy, E. Maler, D. Reed, and M. Sporny, “Decentralized identity: Where DID it come from and where is it going?” IEEE Communications Standards Magazine, vol. 3, no. 4, pp. 10–13, 2019.
[4] K. Friston, “The free-energy principle: a unified brain theory?” Nature reviews neuroscience, vol. 11, no. 2, pp. 127–138, 2010.
[5] F. R. Yu, “From information networking to intelligence networking: Motivations, scenarios, and challenges,” IEEE Network, pp. 1–8, 2021.
[6] A. Tschantz, B. Millidge, A. K. Seth, and C. L. Buckley, “Reinforcement learning through active inference,” arXiv preprint arXiv:2002.12636, 2020.



 发布时间:2023-09-22
发布时间:2023-09-22 作者:光明实验室
作者:光明实验室 浏览:4822次
浏览:4822次