



科研动态 | 光明实验室自主机器智能团队具身智能新进展:基于预训练视觉语言模型的具身智能泛化性研究
![]() 发布时间:2024-05-16
发布时间:2024-05-16![]() 作者:光明实验室
作者:光明实验室![]() 浏览:6447次
浏览:6447次

光明实验室自主机器智能团队的文章ABM: Attention Before Manipulation 被人工智能领域顶级会议、CCF A类会议 IJCAI 2024 接收。
光明实验室的自主机器智能团队的文章“ABM: Attention Before Manipulation”(作者:卓凡、贺颖、于非、李鹏腾、赵哲一、孙喜龙),已被人工智能领域的顶级会议、CCF A类会议 International Joint Conference on Artificial Intelligence (IJCAI 2024) 正式接收。该研究聚焦于基于预训练视觉语言模型的具身智能泛化性。
摘要
视觉语言模型(VLMs)显示出令人兴奋的泛化能力和零样本能力,为解决机器人在现实世界中理解多样化的人类指令和场景语义提供了一种可能的解决方案。现有的方法主要直接将预训练VLMs的语义表示与策略学习相结合。然而,这些方法受限于标注数据的学习,导致对未见过的指令和对象的泛化能力较差。为解决上述局限,本文提出了一种简单的方法,名为“Attention Before Manipulation”(ABM),它充分利用CLIP中的对象知识来提取图像中目标对象的信息。它构建了一个对象掩码场,作为模型更优的目标对象表示,从而将视觉定位与动作预测分离,并有效地获得特定的操作技能。本项研究通过行为克隆的方式将ABM在8个RLBench任务和2个现实世界任务上进行训练。大量的实验表明,此研究的方法在零样本和组合泛化实验设置中显著优于基线方法。
主要内容
机器人学习的主要目标是在工作空间中执行各种任务。为了满足人机交互的需求,机器人需要理解人类指令与环境之间的关系,并执行精确的动作来完成任务。近期的研究提出,通过将指令和视觉图像作为输入,通过模仿学习目标优化端到端模型。然而,这种方法带来了一个挑战,即端到端训练将指令、感知和动作三者的关系紧密联系在一起,即模型只学习到了语义特征与机器人动作之间的映射。具体来说,当感知和指令与训练数据具有相同的分布时,这些方法表现良好,否则表现效果较差。
近期基于语言指导机器人的工作将VLMs的编码器视为特征提取器,训练具有一定泛化能力的模型,并在机器人泛化任务中取得了显著成果。尽管如此,直接将VLMs的语义表示融入策略优化中仍然未能有效解耦指令、感知和动作之间的绑定关系。这些方法导致模型仅实现了特征级别的泛化。换句话说,模型只在遇到与训练数据在语义上接近的指令和图像时表现良好。否则,模型几乎无法应对。原因在于,未见过的图像和指令的语义分布与训练数据不一致,这对模型来说是一个未知分布,因此无法准确预测。这些方法只能实现有限的泛化,无法满足开放性人类指令和对象集的要求。因此,我们需要探索一种更直观且有效的表示方式,以利用VLMs中的丰富的常识,帮助策略实现更好的泛化性能。
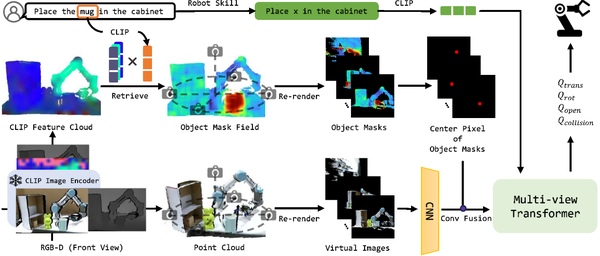
为了解决这个问题,本文提出一种简单的方法,名为“Attention Before Manipulation”(ABM),整体框架图如图1所示。ABM通过提取CLIP中丰富的常识,有效地将视觉推断与动作预测解耦,从而实现对未见过的物体和指令的泛化。与之前的工作不同,本研究设计了一个基于点云的掩码特征场,它标识了目标对象在当前场景点云中的空间位置,以此作为目标对象在训练过程中更优的特征表示来辅助策略学习,提高模型的泛化能力。给定人类指令,本研究首先通过指令分解模块将其分解为目标对象描述和机器人技能描述。然后,本研究通过CLIP提取目标对象描述和图像的语义表示,构建一个对象掩码场(Object Mask Field),将其与原始图像感知和机器人技能结合,共同优化策略。这使得模型能够学习到对象掩码场识别的目标对象、机器人技能和专家动作之间的相互关系。 一旦指令中的目标对象被转换成对象掩码场,模型只需要正确解释对象掩码场中标识目标对象的位置信息,并知道如何应用从专家数据中学习到的机器人技能,就能实现操作新的目标对象,而无需让模型事先理解指令中新的目标物体描述。这种方式使我们的系统能够利用从专家数据中学习到的机器人技能来实现对从未见过的物体的零样本泛化,并完成来自不同训练任务的目标物体组合而成的操作任务,并且无需进一步微调。
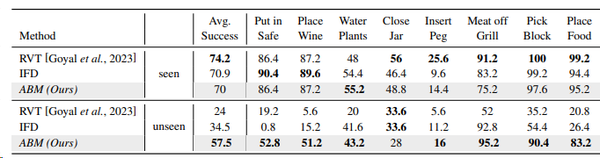
ABM在RLBench环境下多任务验证结果如表1所示。“unseen”代表模型在零样本泛化验证集中的性能,其中目标对象和指令在训练过程没有出现过。 “seen”表示模型在原始验证集中的性能,其中目标对象和指令在训练过程出现过。本研究通过对每个任务的25个变体进行五次评估取平均值作为每个任务在“seen”和“unseen”下的成功率。
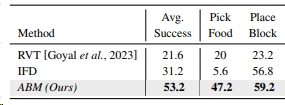
ABM在RLBench环境下组合任务的验证结果如表2所示。组合任务中的目标物体来自于不同的训练任务。如Pick Food的目标物体由原来的Block变为Place Food训练任务的目标物体Food。以此验证模型在组合任务中的泛化能力。
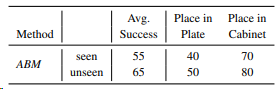
ABM在现实世界环境中验证模型性能结果如表3所示。每个现实任务采用20个专家数据进行训练,并在“seen”和“unseen”下验证模型性能。
仿真和真实世界实验结果表明,ABM相比于基线方法具有强大的泛化能力和零样本能力,同时具备一定组合学习到的机器人技能的能力。
原文
Fan Zhuo, Ying He, Fei Yu, Pengteng Li, Zheyi Zhao, Xilong Sun. ABM: Attention Before Manipulation, International Joint Conference on Artificial Intelligence, accepted, Aug. 2024.
参考文献
[1] Shridhar M, Manuelli L, Fox D. Cliport: What and where pathways for robotic manipulation[C] //Conference on robot learning. PMLR, 2022: 894-906.
[2] Shen W, Yang G, Yu A, et al. Distilled feature fields enable few-shot language-guided manipulation[J]. arXiv preprint arXiv:2308.07931, 2023.
[3] Wang Y, Li Z, Zhang M, et al. D $^ 3$ Fields: Dynamic 3D Descriptor Fields for Zero-Shot Generalizable Robotic Manipulation[J]. arXiv preprint arXiv:2309.16118, 2023.
[4] Stone A, Xiao T, Lu Y, et al. Open-world object manipulation using pre-trained vision-language models[J]. arXiv preprint arXiv:2303.00905, 2023.
[5] Goyal A, Xu J, Guo Y, et al. Rvt: Robotic view transformer for 3d object manipulation[C]//Conference on Robot Learning. PMLR, 2023: 694-710.
END
素材来源 丨光明实验室自主机器智能团队
编 辑 丨 李沛昱



 发布时间:2024-05-16
发布时间:2024-05-16 作者:光明实验室
作者:光明实验室 浏览:6447次
浏览:6447次