



科研动态 | 光明实验室城市三维创新团队最新研究工作 LGTM: 局部到全局的文本驱动的人体动作扩散模型 光明实验室 光明实验室
![]() 发布时间:2024-06-27
发布时间:2024-06-27![]() 作者:光明实验室
作者:光明实验室![]() 浏览:6060次
浏览:6060次

光明实验室城市三维创新团队的研究工作LGTM: Local-to-Global Text-Driven Human Motion Diffusion Model(LGTM: 局部到全局的文本驱动的人体动作扩散模型)已发表在计算机图形学国际最顶级旗舰会议SIGGRAPH 2024上。
主要内容
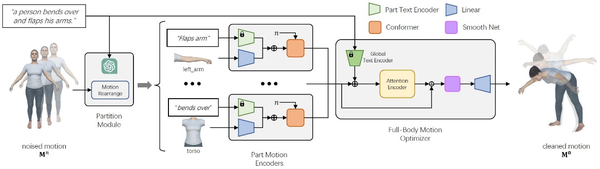
该工作提出了一种名为LGTM的局部到全局的文本到人体动作的生成扩散模型,用以应对传统方法难以从动作文本描述准确生成语义一致的人体动作的挑战。具体来说,LGTM首先将全局动作文本描述分解为每个身体部位的局部描述,然后通过独立的身体部位运动编码器对齐这些部位的具体语义,最后使用全身优化器改进动作生成结果并保证整体的连贯性。实验结果表明,LGTM在生成局部准确、语义对齐的人体动作方面取得了显著改进。
近年来随着多模态模型、AIGC和文生动画的发展,许多研究工作展示出强大的动画数字资产生成能力,为电影、游戏、AR/VR行业注入了新的动力。然而在实际工业应用中,往往要求高质量的数字资产、高度可控的动画生成和高精细程度的细节,这给计算机动画研究领域带来新的机遇与挑战。LGTM尝试解决生成局部上精细可控、全局一致的人体动作,对未来工作具有重要的参考意义。
项目主页
https://vcc.tech/research/2024/LGTM
代码开源

END
素材来源 丨光明实验室城市三维创新团队
编 辑 丨 李沛昱



 发布时间:2024-06-27
发布时间:2024-06-27 作者:光明实验室
作者:光明实验室 浏览:6060次
浏览:6060次