



科研动态 | 光明实验室生成式大模型团队新进展:自适应循环思考为小模型赋能 —— 小模型推理新路线
![]() 发布时间:2025-02-21
发布时间:2025-02-21![]() 作者:光明实验室
作者:光明实验室![]() 浏览:3258次
浏览:3258次

Zero-Token Transformer (ZTT):一项深度循环推理的新进展
研究提出的Zero-Token Transformer (ZTT)架构能够在推理过程中有效扩展计算深度,同时避免依赖传统的扩展tokens的方式。这项技术使得即便是小模型,也能通过参数循环来达到较好的性能,并且能够自适应地决定推理的深度——对于复杂的问题进行多次深度推理,而对简单的问题则减少不必要的计算,从而显著提高计算效率。
ZTT的最大创新之一在于它通过精细的层次化设计,避免了传统循环模型中不同层级功能混杂的情况。在过去的模型中,不同的循环层通常需要承担多个任务,导致了计算资源的浪费与性能的降低。而Zero-Token Transformer则通过解耦头部和尾部层,仅对中间层进行循环计算,进而提升了推理的深度和效率。
Zero-Token Transformer 的创新性架构
Zero-Token Transformer结合了头尾解耦的循环架构和Zero-Token机制,通过引入一个可学习的零令牌,能够动态调整每个层级的推理步骤。具体来说,Zero-Token Transformer的创新架构体现在以下几个方面:
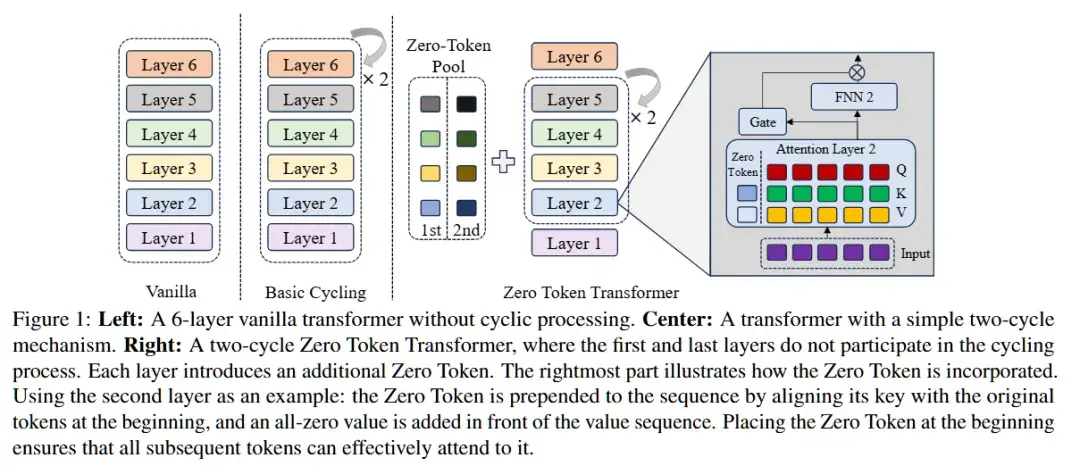
1. 头尾解耦架构:ZTT通过固定模型的头部和尾部层,仅对中间层进行循环计算,避免了传统方法中所有层都参与推理循环所带来的计算冲突和效率损失。这样,模型能够更专注于处理核心任务。
2. Zero-Token机制:每个循环中的中间层会引入一个零令牌,这个零令牌携带零值的Value和可训练的Key值,并与原始tokens一起进入注意力机制。它类似于一个“提示符”(prompt),提醒当前层该执行什么样的计算,并根据当前推理的需要动态决定是否继续进行推理,或者跳过当前计算,从而节省不必要的计算资源。
3. 动态退出机制:基于Zero-Token的注意力得分,模型能够判断是否继续进行推理。当某一层的Zero-Token得到较高关注度时,意味着进一步推理不会带来额外价值,此时模型可以提前退出,进一步提高计算效率。
ZTT的核心优势与实验成果
相较于传统的固定深度Transformer模型,ZTT能够实现更深的推理,同时大幅度提高计算效率。具体的优势体现在以下几方面:
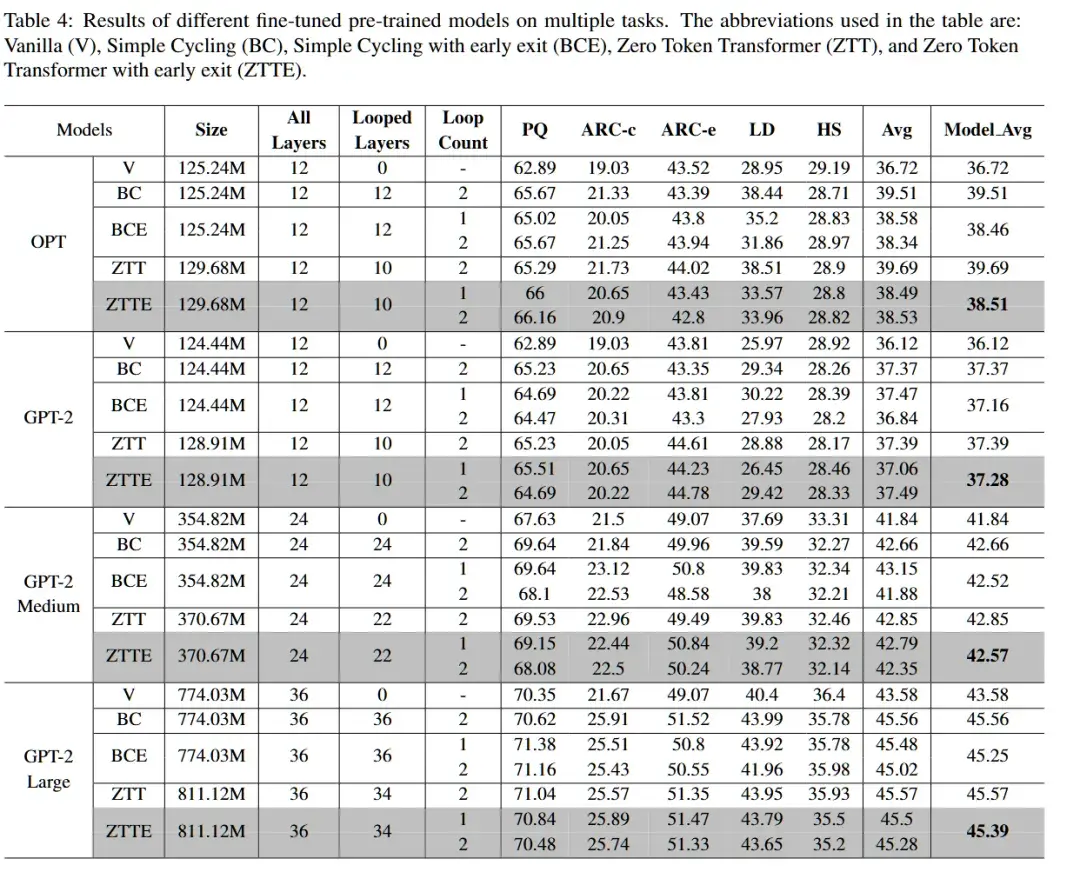
1. 性能提升:在从头训练模型的实验中,ZTT表现出了比传统的原始Transformer(V)或简单堆叠(BC)模型更优秀的性能。其精细的计算控制和参数共享机制,使得在有限计算预算下,ZTT能够在多个任务上获得较好的结果。
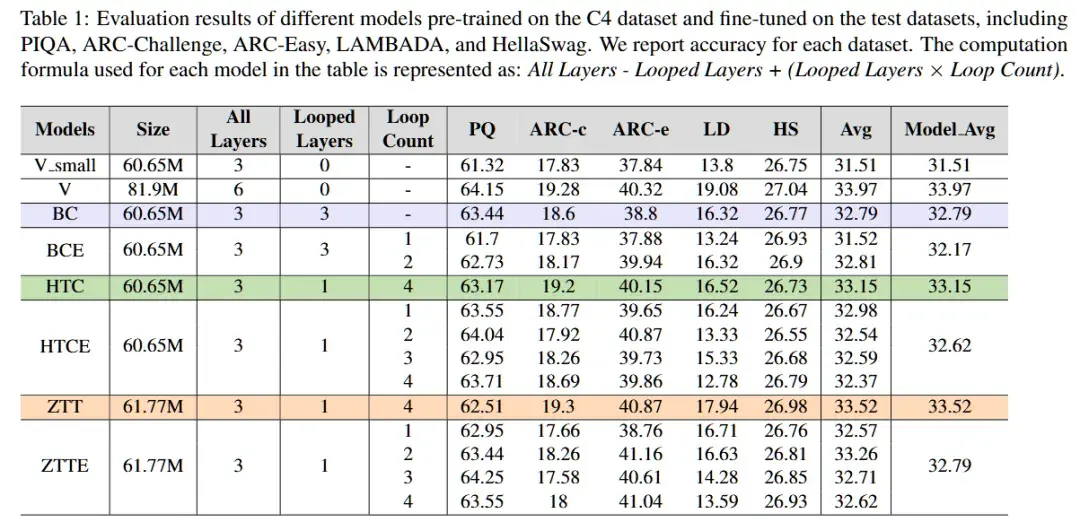
2. 自适应的停止机制:ZTT通过对Zero-Token的关注度进行评估,能够动态判断当前推理是否充分,并根据需要决定是否提前退出计算。这一机制不仅避免了不必要的计算负担,还大大提高了推理的效率。在实验中,当Zero-Token的关注度达到一定阈值时,模型会自动停止进一步的计算,节省了计算资源,同时仍能保持较高的推理准确性。例如,在不同的循环次数下,Zero-Token的注意力得分逐渐增大,表明模型对后续推理的依赖减少,从而提前终止循环,避免了冗余的计算。
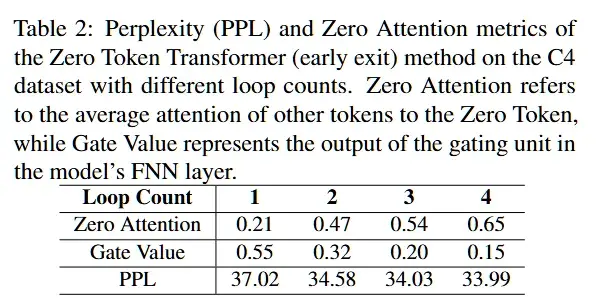
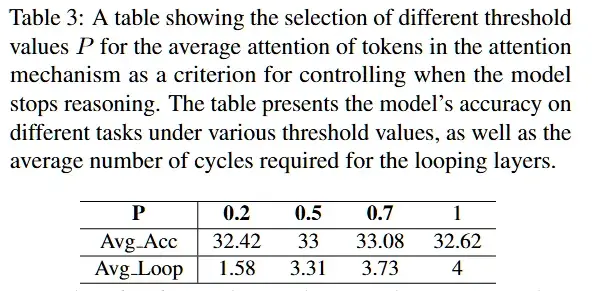
3. 适配现有模型:ZTT不仅能够与当前的其他方法结合,还能通过微调已有的预训练模型来提升性能,兼容性非常强。通过将Zero-Token机制与传统的Transformer架构结合,ZTT能够充分发挥现有模型的优势,并在此基础上进行性能提升。实验结果表明,ZTT在多个任务上的表现优于其他方法,特别是在基于预训练模型进行微调时,Zero-Token Transformer能够有效提升模型的推理效率和准确性,同时保持较低的计算成本。这使得ZTT成为一种在资源有限的环境下,仍然能够优化大规模语言模型推理能力的重要工具。
广阔的应用前景与未来计划
Zero-Token Transformer的成功提出,为未来的大规模语言模型推理和优化提供了新的思路。该方法不仅在从头训练和微调现有模型时表现出色,还为资源受限的场景下实现大规模语言模型提供了新的路径。论文将于近期发布于arXiv。未来,研究团队计划进一步优化ZTT架构,探索更高效的学习率策略、更优化的训练数据组合以及加速器支持,从而继续提升训练效率。
光明实验室生成式大模型团队始终秉持着开放、共享、合作的理念,致力于将最先进的人工智能技术应用于实际场景中,为更多人带来便利与福祉。同时,团队也十分期待与各界同仁携手并进,共同探索大模型应用的无限可能,共创更加美好的未来。
目前团队正在招聘大模型算法岗位实习生,有意向者可投递简历至: jiangwenhao@gml.ac.cn。
END
素材来源 丨生成式大模型团队
编 辑 丨 李沛昱
审 核 丨 郭 锴



 发布时间:2025-02-21
发布时间:2025-02-21 作者:光明实验室
作者:光明实验室 浏览:3258次
浏览:3258次