



科研动态 | 光明实验室自主机器智能团队具身智能新进展:基于大语言模型的具身智能语义地图与导航研究
![]() 发布时间:2024-07-27
发布时间:2024-07-27![]() 作者:光明实验室
作者:光明实验室![]() 浏览:6023次
浏览:6023次

01 摘要
语义和空间信息的准确感知对于执行语言驱动导航任务的机器人至关重要。现有方法利用视觉语言模型从环境中提取语义信息并构建地图。然而,由于这些模型自身的泛化性和准确性受限,所构建的地图可能不够准确和全面,从而影响导航任务的准确性。受大模型出色的分类和分割能力的启发,本研究引入了一种使用大模型构建的语义地图。我们利用大模型对机器人的视频流进行语义分割,并将语义信息融合到地图上。此外,该地图与接收自然语言指令的大型语言模型(LLMs)结合使用,以完成导航任务。大量的模拟环境实验表明,本方法在语言驱动的导航任务中优于现有方法。
02 主要内容
在执行自然语言导航任务时,机器人要根据语言指令理解人类的意图,导航到正确的位置。模块化的方法将整个导航过程解剖为感知,决策,执行三个部分:感知模块通过传感器数据构建语义地图,决策模块根据指令和地图规划路径,执行模块将决策转化为实际行动。这种方法能够使每个模块独立优化和改进,提升整体系统的灵活性和适应性。尽管这种方法取得了成功,但先前的研究受限于模型的性能,对语义地图的构建不够准确不够全面,也无法理解人类的一些复杂指令,导致机器人只能遵循固定的指令导航到十分有限的地点。
为了解决这些问题,大模型的出现激发了有价值的思路。一些方法使用大量的互联网数据训练而成的视觉-语言模型从环境中提取视觉特征后,将视觉特征与点云一一对应来构造语义地图,通过文本-视觉对齐来在地图中查询感兴趣的区域,并结合大语言模型来处理更复杂的自然语言指令。这些方法提高了机器人对环境的感知能力和对自然语言指令的理解能力,从而在语言驱动的导航任务中表现更加出色,并具备了开放词汇查询的能力。然而,它们也存在一定的局限性,这些视觉-语言模型仍然存在泛化性不足、准确性不够的情况,这可能会影响语义地图的准确性和泛化性,从而影响导航的成功率。因此,提出一种方法来构造更准确更全面的语义地图用以执行自然语言导航任务仍然是一个具有挑战性的问题。
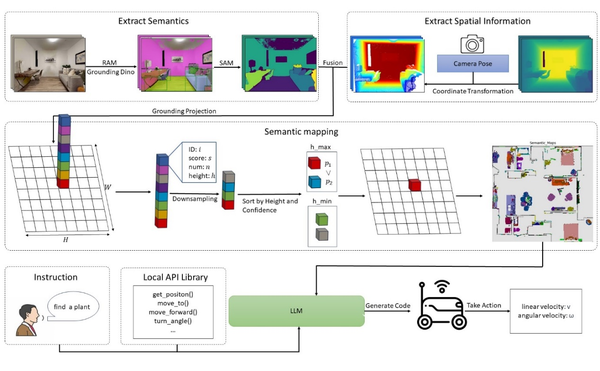
对此,本研究提出基于大模型的集成语义地图的自然语言导航方法,名为“A Language-Driven Navigation Strategy Integrating Semantic Maps and Large Language Models”,整体框架图如图1,算法流程图如图2所示。通过大型视觉模型构造精确的语义地图,结合大型语言模型处理自然语言指令,实现了可靠的机器人自然语言导航过程。
该算法主要特征:

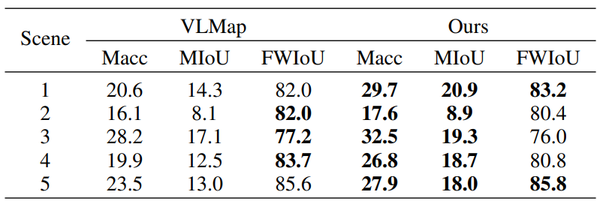
通过与真值地图的对比展示了语义地图的准确性如表1所示。揭示了本研究的方法比基准方法的平均准确率(Macc),平均交并比(MIoU)更高,两者的频率加权交并比(FWIoU)接近。
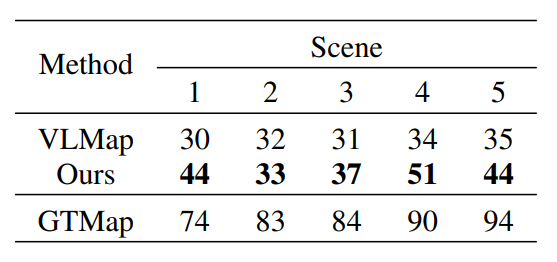
本研究方法在Habitat simulator环境下导航任务的验证结果如表2所示。导航任务将场景中任一标签作为目标,并认为最终距目标一米之内导航成功,以此验证方法导航成功率。表2揭示了本研究的导航成功率比基准方法(VLMap)更高,离上限(GTMap 为采用真值地图的导航)还有差距。
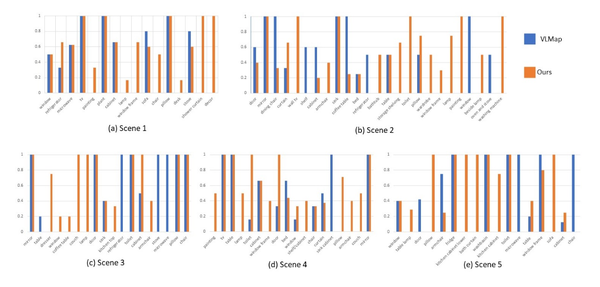
其中各标签导航成功率结果如图3所示。图中展示了本研究方法成功的标签更多且整体准确率更高,说明泛化性和准确性比基准方法更好。
原文
Zhengjun Zhong, Ying He, Pengteng Li, Fei Yu*, and Fei Ma. A Language-Driven Navigation Strategy Integrating Semantic Maps and Large Language Models. State Conference: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Current status: Accepted. Submission number: 1369.
参考文献
[1] C. Huang, O. Mees, A. Zeng, and W. Burgard, “Visual Language Maps for Robot Navigation,” in Proceedings of 2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 10 608– 10 615.
[2] Y. Zhang, X. Huang, J. Ma, Z. Li, Z. Luo, Y. Xie, Y. Qin, T. Luo, Y. Li, S. Liu, et al., “Recognize Anything: A Strong Image Tagging Model,” arXiv preprint arXiv:2306.03514, 2023.
[3] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al., “Segment Anything,” arXiv preprint arXiv:2304.02643, 2023.
[4] B. Chen, F. Xia, B. Ichter, K. Rao, K. Gopalakrishnan, M. S. Ryoo, A. Stone, and D. Kappler, “Open-vocabulary Queryable Scene Representations for Real World Planning,” in Proceedings of 2023 IEEE International Conference on Robotics and Automation, 2023, pp. 11 509–11 522.
[5] T. Wang, X. Mao, C. Zhu, R. Xu, R. Lyu, P. Li, X. Chen, W. Zhang, K. Chen, T. Xue, et al., “Embodiedscan: A holistic multi-modal 3d perception suite towards embodied ai,” arXiv preprint arXiv:2312.16170, 2023.
END
素 材 丨 光明实验室自主机器智能团队
编 辑 丨 李沛昱



 发布时间:2024-07-27
发布时间:2024-07-27 作者:光明实验室
作者:光明实验室 浏览:6023次
浏览:6023次