



科研动态 | 光明实验室媒体智能团队综述论文被计算机领域顶级期刊Information Fusion录用
![]() 发布时间:2024-11-01
发布时间:2024-11-01![]() 作者:光明实验室
作者:光明实验室![]() 浏览:5020次
浏览:5020次

近日,光明实验室媒体智能团队综述文章“Generative Technology for Human Emotion Recognition: A Scoping Review”(作者:Fei Ma,Yucheng Yuan,Yifan Xie,Hongwei Ren,Ivan Liu,Ying He,Fuji Ren,Fei Richard Yu,Shiguang Ni)被中科院一区Top期刊Information Fusion(影响因子:14.7)录用。该论文对情感识别领域的生成技术进行了全面的梳理和总结,为未来的研究提供了重要的方向和启示。
论文背景与意义
情感计算是人工智能的重要研究领域之一,其目标是让机器具备理解和响应人类情感的能力。情感识别作为情感计算的核心任务,旨在通过语音、面部图像、文本和生理信号等多种模态识别和解释人类情感状态。近年来,生成模型在情感识别中的应用取得了显著进展,这些模型凭借其强大的数据生成能力,成为推动情感识别技术发展的重要工具。然而,目前尚缺乏综述以深入总结生成技术在情感识别上的应用。为填补这一空白,该论文对截至2024年6月的330多篇研究论文进行了系统化的回顾。
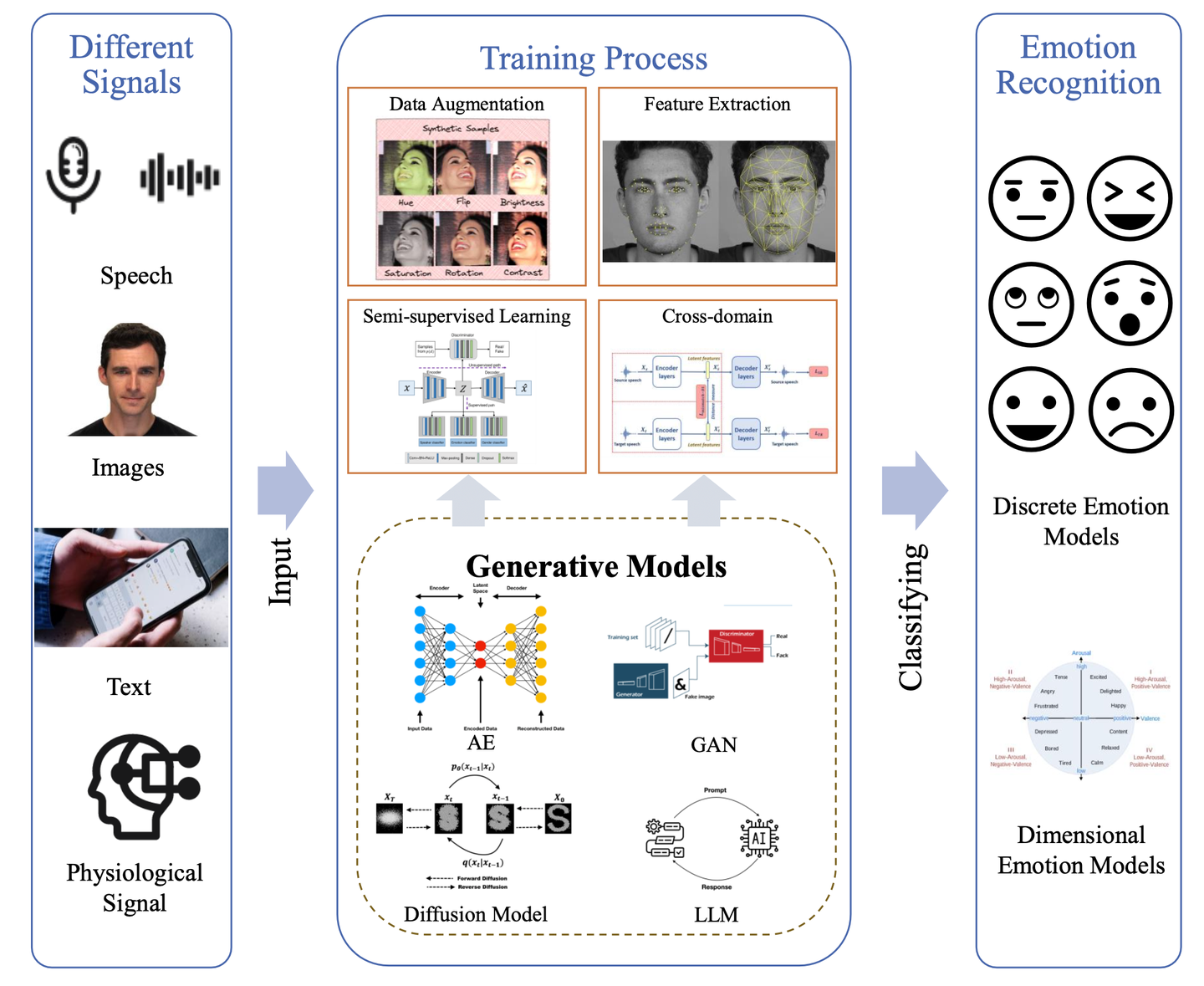
主要内容
论文首先介绍了当前生成模型在情感识别中的应用现状,具体包括自动编码器、生成对抗网络、扩散模型和大语言模型等。随后,论文对常用的基于语音、面部图像、文本和生理信号等不同模态的情感识别数据集进行了梳理,例如FER2013、AFEW、IEMOCAP、RAVDESS和CMU-MOSEI等。这些数据集为研究者提供了丰富的研究资源。其次,论文从多角度展示了生成模型在情感识别领域的研究进展,例如在数据增强方面,生成模型通过生成与真实情感数据高度相似的样本,有效提升了模型的适应能力。在特征提取方面,生成模型通过学习情感数据的有效特征表示,提升了识别性能。半监督学习和跨领域识别是生成模型在情感识别中的另一个重要应用,能够缓解标注数据匮乏和不同领域数据分布差异带来的挑战。
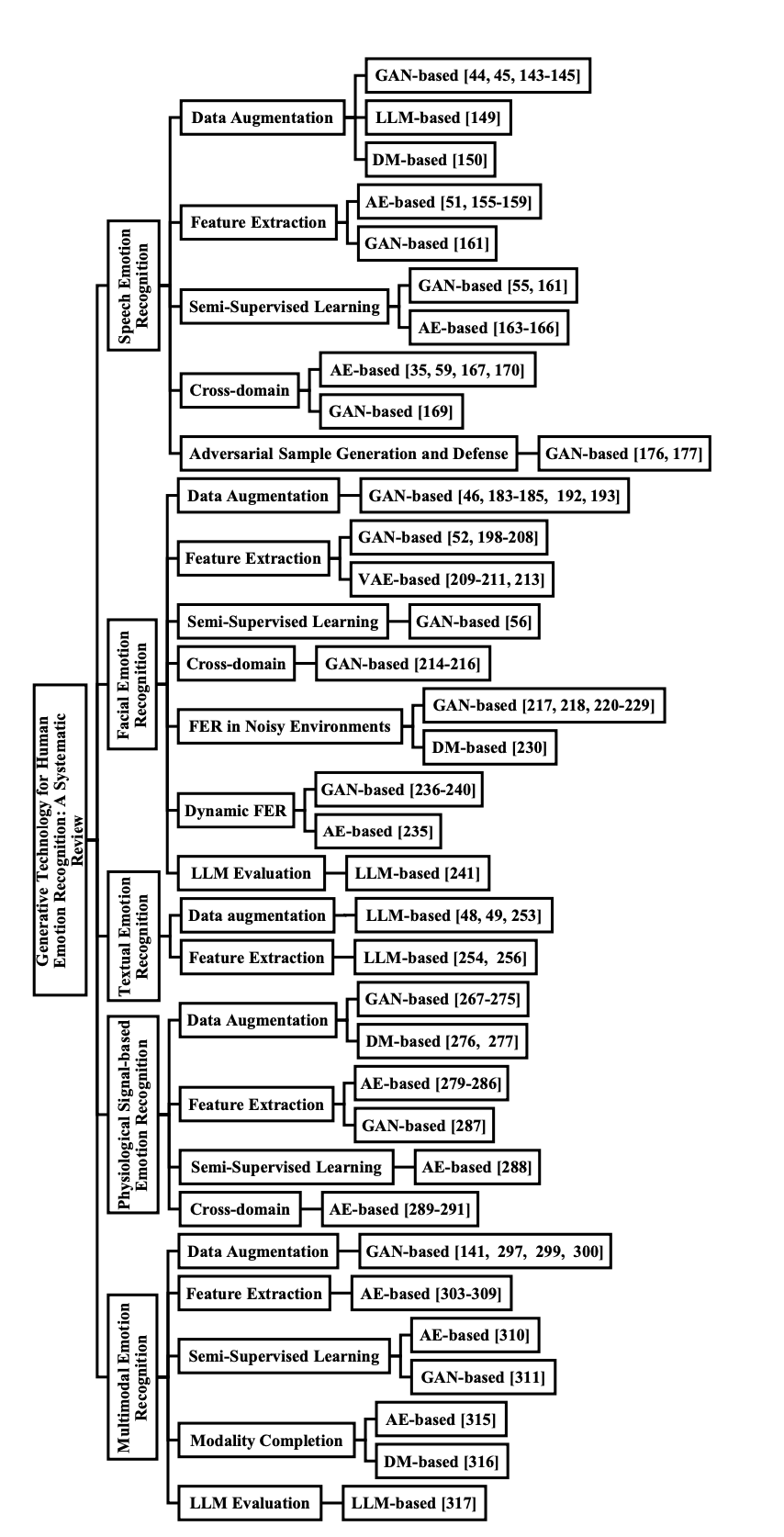
未来研究方向
论文在总结现有研究成果的基础上,也为生成模型在情感识别领域的未来发展指明了方向,包括探索将大语言模型与扩散模型结合应用于情感识别,以及将强化学习和联邦学习等技术与生成模型结合,以更好地模拟情感的复杂依赖关系和时间演化。此外,生成技术在虚拟现实和增强现实中的应用也值得进一步探索,以提升用户体验。
光明实验室媒体智能团队致力于从事(1)图片及视频的生成与编辑、(2)数字人及交互生成、(3)多模态大模型与情感智能等方面的工作,长期招聘全职序列(研究员、副研究员、工程师)与研究型实习生,欢迎联系与交流:mafei@gml.ac.cn。
END
素材来源 丨光明实验室媒体智能团队
编 辑 丨 李沛昱
审 核 丨 郭 锴



 发布时间:2024-11-01
发布时间:2024-11-01 作者:光明实验室
作者:光明实验室 浏览:5020次
浏览:5020次