



助力国产算力生态!光明实验室基于线性RNN多模态VisualRWKV大模型发布
![]() 发布时间:2024-12-10
发布时间:2024-12-10![]() 作者:光明实验室
作者:光明实验室![]() 浏览:5104次
浏览:5104次

论文标题:VisualRWKV: Exploring Recurrent Neural Networks for Visual Language Models
作者:Haowen Hou, Peigen Zeng, Fei Ma, Fei Richard Yu。
COLING,国际计算语言学会议(International Conference on Computational Linguistics),是自然语言处理和计算语言学领域的顶级国际会议。COLING 2025将于2025年1月19日至24日在阿联酋阿布扎比召开。VisualRWKV论文已被COLING 2025主会接收。另外,该模型针对华为昇腾910B(NPU)进行了优化测试,并充分利用其高效算力,显著提升了推理效率和性能表现,支持开发者基于国产算力平台进一步探索多模态任务,促进国产算力生态发展。
论文:
https://arxiv.org/abs/2406.13362
代码:
https://github.com/howard-hou/VisualRWKV
摘要
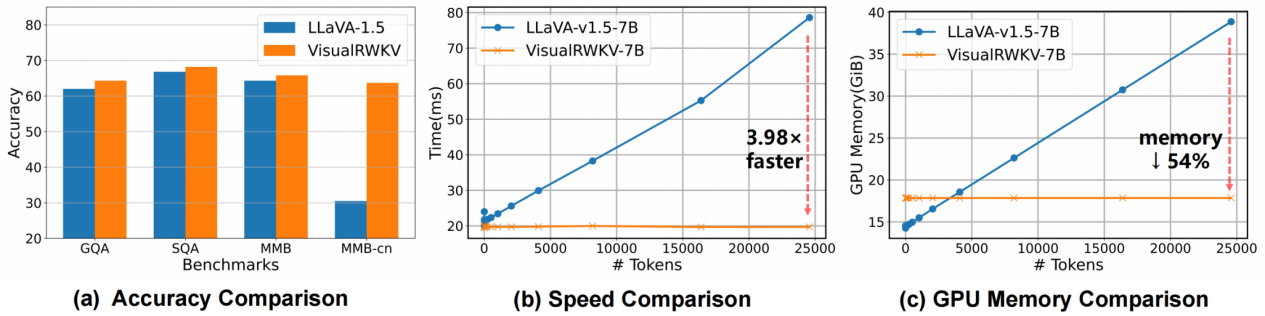
视觉语言模型(VLMs)随着大型语言模型的成功迅速发展。然而,将高效的线性循环神经网络(RNNs)架构整合到VLMs中的尝试还相对较少。在这项研究中,我们提出了VisualRWKV,这是线性RNN模型首次应用于多模态学习任务,利用了预训练的RWKV语言模型。我们提出了数据依赖的递归和三明治提示词来增强我们的建模能力,以及一个2D图像扫描机制来丰富视觉序列的处理。广泛的实验表明,VisualRWKV在各种基准测试上达到了与基于Transformer的模型如LLaVA-1.5相竞争的性能,如图1所示。同时,当上下文长度达到24K时,推理速度比LLaVA-1.5快3.98倍,GPU显存占用少54%。
研究背景
视觉语言模型发展:大型语言模型在自然语言处理中表现出色,视觉语言模型(VLMs)通过整合视觉和文本信息,在解决视觉问题和推进视觉 - 语言任务方面潜力巨大,但现有模型因 Transformer 架构自注意力机制存在计算和内存复杂度高的问题,限制了其在边缘设备的应用。
线性RNN 模型优势:RWKV模型作为新型递归神经网络架构,在大规模数据性能上超越Transformers,具有线性可扩展性,为长序列建模瓶颈提供解决方案,但在多模态任务应用方面的研究较少。
VisualRWKV 模型设计
VisualRWKV的整体模型结构如图2所示,其中红字是VisualRWKV核心创新点。分别是数据依赖循环(Data-dependent Recurrence),三明治提示词(Sandwich Prompt)和双向扫描(Bidirectional Scanning)。
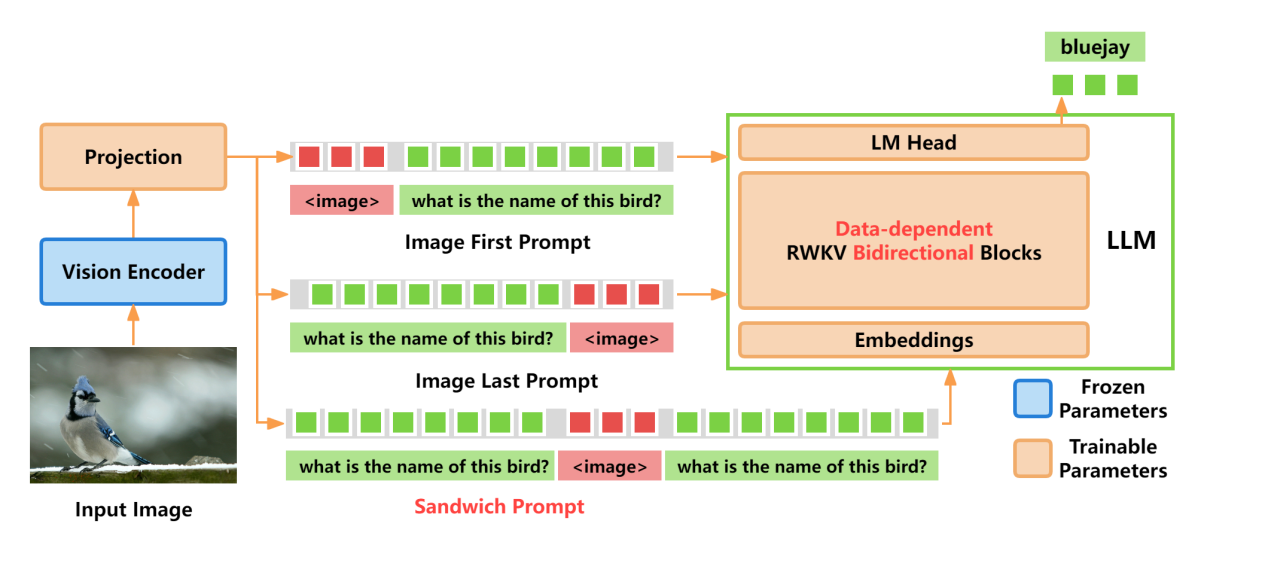
✦ 三明治提示词
如图2所示,设计了图像在前提示、图像在后提示和三明治提示三种方法,实验表明三明治提示效果最佳,能让模型在处理图像前回顾指令,更有针对性提取信息,减轻因图像标记减少导致的信息丢失。
✦ 数据依赖循环
Data-dependent Recurrence可以有效增强RWKV模型的能力和容量,如图3所示。
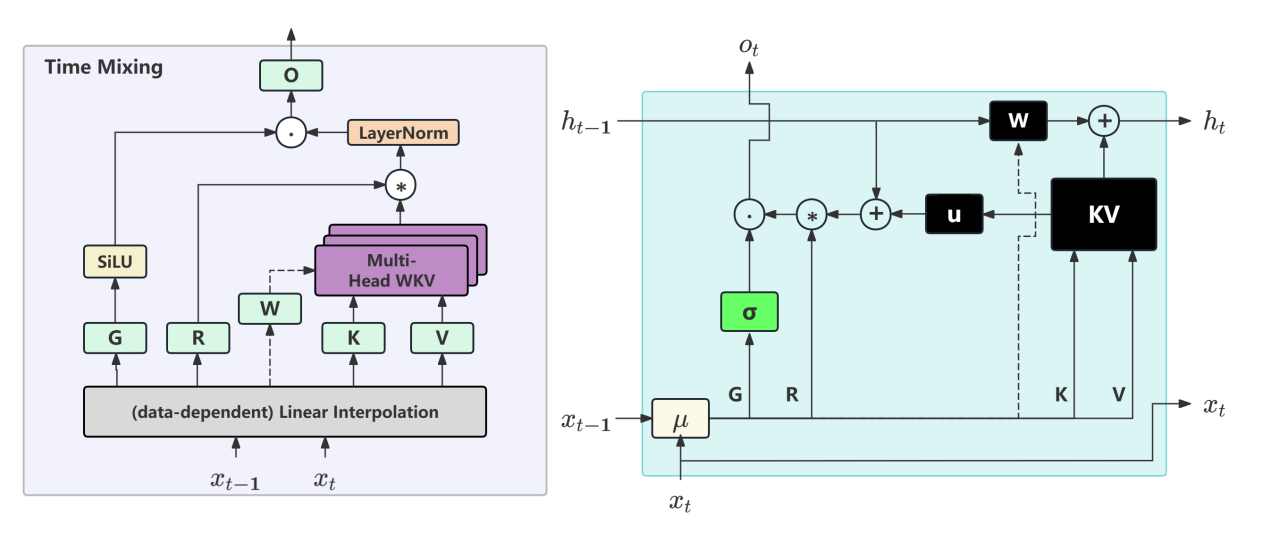
✦ Data-dependent Recurrence主要包括如下2点设计:
☆数据依赖的Token Shift:通过定义低秩适应(lora)和数据依赖线性插值(ddlerp),动态分配新数据与现有数据比例,拓宽模型容量。
☆数据依赖的时间混合:将时间衰减向量从固定参数变为动态,使模型能更灵活适应输入数据,提升性能
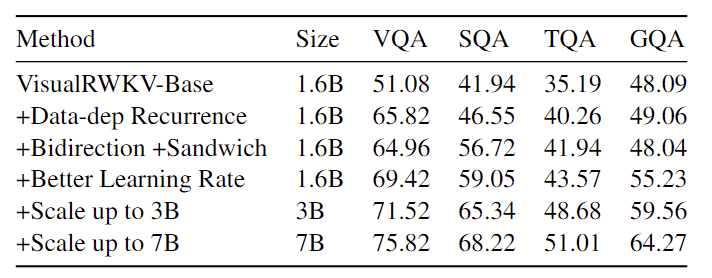
如下表所示,VisualRWKV引入Data-dependent Recurrence后,在VQA测试集上效果上涨了接近15个点,非常让人印象深刻。
图像扫描机制
如图4所示,我们探索了单向块、双向块和多向块三种变体,实验显示单向扫描不适合处理 2D 视觉信息,双向扫描在处理多模态学习任务的 2D 视觉信息方面表现较好。因为仅仅是调整不同层的扫描方向,也不并会增加模型总体的计算量。

实验结果
✦ 性能比较
VisualRWKV 在 8 个基准测试中的 3 个取得最佳性能,在 SQA 基准测试中排名第二,与 LLaVA-1.5 相比,在多个基准测试中表现更优,尤其在 MMB-cn中文测试集上领先明显,表明 RWKV 语言模型多语言能力更强。表2展示了我们提出的VisualRWKV模型与一些最先进的多模态大型语言模型的比较。VisualRWKV在8个基准测试中的3个中取得了最佳性能,在SQA基准测试中排名第二。与规模参数相似且多模态训练数据量相同的LLaVA-1.5 7B相比,我们的模型(VisualRWKV-7B)在4个基准测试中表现更好:SQA(68.2%对66.8%)、GQA(64.3%对62.0%)、MMB(65.8%对64.3%)和MMB-cn(63.7%对30.5%)。值得注意的是,VisualRWKV和LLaVA-1.5使用了完全相同的训练数据。然而,在MMB-cn中文测试集上,VisualRWKV显示出了显著的领先优势。这可能表明RWKV语言模型具有更强的多语言能力。这些有希望的结果不仅证实了VisualRWKV模型的有效性,还突显了线性RNN模型在多模态学习任务中的重要潜力。
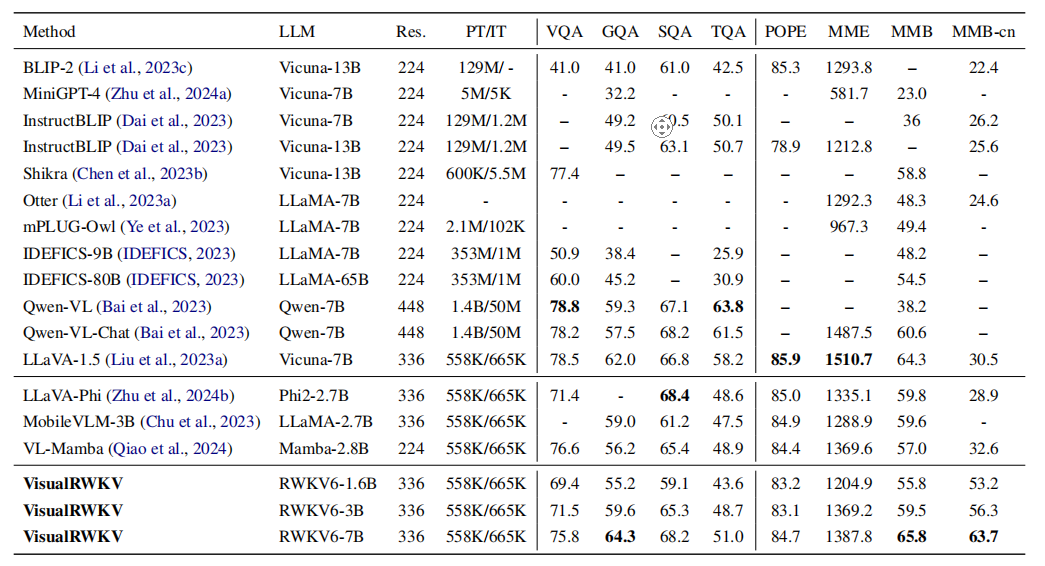
表 2 在8个基准测试上与最先进方法的比较。由于空间限制,基准测试名称被缩写。VQA;GQA;SQA:ScienceQA-IMG;TQA:TextVQA;POPE;MME;MMB:MMBench;MMB-cn:MMBench-CN。PT和IT分别表示预训练和指令调优阶段涉及的样本数量。"Res."代表“分辨率”。
✦ 消融实验
表3展示了在三种提示方法中,我们提出的三明治提示表现最佳,传统的先图像后提示排在第二位,而先图像后提示的效果最差。三明治提示增强效果的原因如下:通过让模型在处理图像之前先回顾指令,三明治提示有助于更有针对性地从图像中提取信息,从而加强图像信息检索过程中的条件方面。然而,仅仅将指令放在图像之前是不够的。我们观察到,图像后提示的效果明显较差。仅仅将指令放在图像前面是不充分的;我们发现图像后提示的效果明显较差。这是因为线性RNN模型在处理图像后往往会忘记指令信息,需要重复指令以获得更好的结果。此外,我们的研究表明,三明治提示能够有效减轻由于图像标记减少导致信息丢失的问题,即使只有少量的图像标记也能保持好的结果。

我们比较了三种图像扫描机制:单向扫描(UniDir)、双向扫描(BiDir)和多向扫描(MultiDir)。如表4所示,UniDir的表现最差,因为它天生不适合处理2D视觉信息。BiDir和MultiDir在各种基准测试评估中显示出相似的结果,但BiDir在大多数情况下表现更好,突显了它在处理多模态学习任务中的2D视觉信息方面的优势。
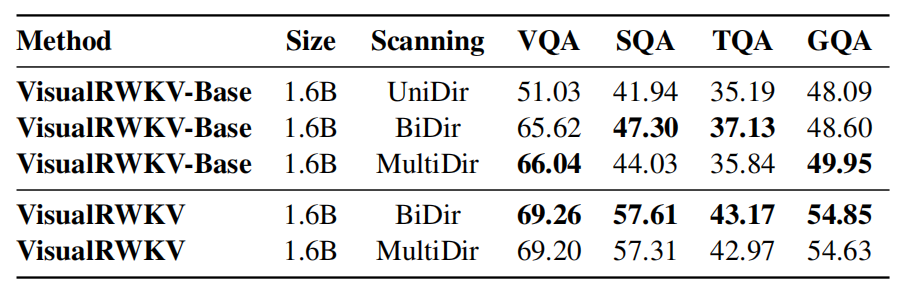
✦ 效率分析与文本能力
与LLaVA-1.5相比,在24K上下文时,VisualRWKV推理速度快3.98倍,GPU内存消耗降低54%。此外,VisualRWKV在文本能力上未出现退化,在多语言文本能力上与文本专用的RWKV基本一致,得益于多语言ShareGPT4数据的整合。
✦ 国产算力
VisualRWKV不仅在算法上实现了多模态学习任务的创新性突破,也在国产算力生态建设上作出了贡献。该模型针对华为昇腾910B(NPU)进行了优化测试,并充分利用其高效算力,显著提升了推理效率和性能表现。

根据表5的测试数据,VisualRWKV在昇腾910B上运行时表现优异,与基于英特尔至强5320(CPU)的运行相比,性能大幅提高。
在 NPU 平台上运行时,VisualRWKV-7B 模型的延迟为 0.062 秒,相较于 CPU 平台上的 0.266 秒提升显著。在相同模型规模下,NPU设备上的推理速度远高于CPU。例如,VisualRWKV-7B在NPU上的每秒生成速度达16.001 tokens,而在CPU上仅为3.748 tokens,性能提升超过4倍。
VisualRWKV的开源版本已发布到国内知名的开源社区魔乐社区 :
(https://modelers.cn/models/youyve/visualrwkv-6/tree/main)
支持开发者基于国产算力平台进一步探索多模态任务,同时促进国产算力生态发展。
国产算力支持为 VisualRWKV模型提供了坚实的基础,未来随着国产硬件与 RNN 模型的进一步结合,VisualRWKV有望在更多应用场景中大放异彩,助力国产AI生态实现新的突破。
END
素材来源 丨光明实验室基础智能研究团队
编 辑 丨 李沛昱
审 核 丨 郭 锴



 发布时间:2024-12-10
发布时间:2024-12-10 作者:光明实验室
作者:光明实验室 浏览:5104次
浏览:5104次