



科研动态 丨 大数据智能处理与分析团队两篇论文入选AAAI 2025:突破全景图像超分辨与统一图像编码技术
![]() 发布时间:2024-12-30
发布时间:2024-12-30![]() 作者:光明实验室
作者:光明实验室![]() 浏览:4725次
浏览:4725次

大数据智能处理与分析团队的两篇论文:
1)“Fast Omni-Directional Image Super-Resolution: Adapting the Implicit Image Function with Spherical Geometric Priors”(作者:Xuelin Shen,Yitong Wang,Silin Zheng,Kangxiao,Wenhan Yang,Xu Wang);
2) “Unified Coding for Both Human Perception and Generalized Machine Analytics with CLIP Supervision” (作者:Kangsheng Yin,Quan Liu,Xuelin Shen,Yulin He,Wenhan Yang,Shiqi Wang)
均被人工智能领域顶级会议AAAI 2025接收。两篇文章第一作者均为大数据智能处理与分析团队联培研究生/科研人员。
论文1:
Fast Omni-Directional Image Super-Resolution: Adapting the Implicit Image Function with Spherical Geometric Priors
内容简介全景图像因其沉浸式和交互式体验应用而受到研究关注,特别是在AR/VR应用中需要极高的分辨率。等矩形投影(ERP)的非均匀过采样特性是全景图像超分辨率的一个独特挑战。先前的方法通过设计复杂的球面卷积或多面体重投影方法来达到性能提升,代价是繁琐的处理过程与较慢的推理速度。此外,由于全景图像的使用场景、播放设备种类繁多,已有方法的固定倍率超分辨率难以满足实际应用需求。
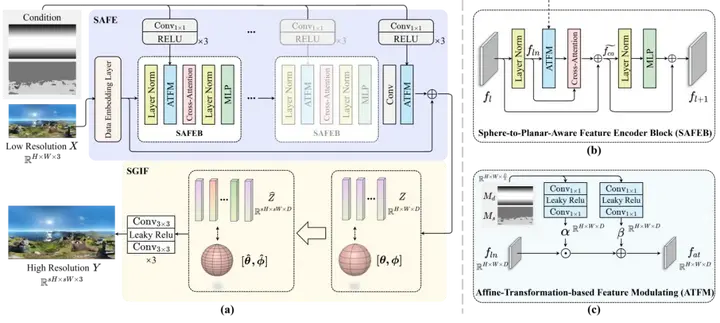
在此背景下本工作提出了一种方法(FAOR),能够进行快速、任意倍率的全景图像超分辨率。关键点在于将隐式图像函数从平面图像域迁移到ERP图像域,利用全景图像的球面几何先验提取潜在表示和重建图像。在潜在表示阶段采用一对像素级和语义级球面到平面的扭曲映射来对潜在特征进行仿射变换,嵌入球面特性。在图像重建阶段引入球面重采样,在不引入额外参数的情况下将平面隐式图像函数与球面几何对齐。
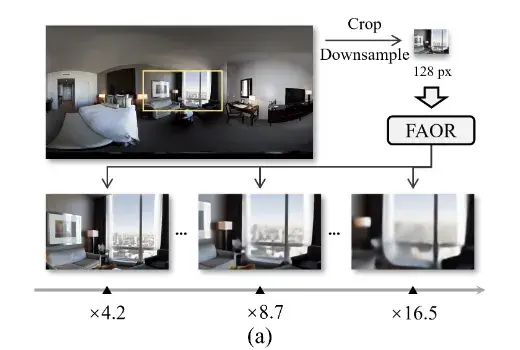
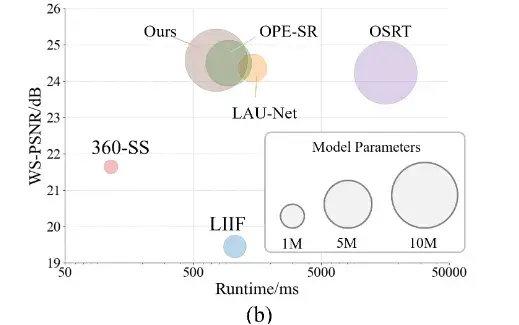
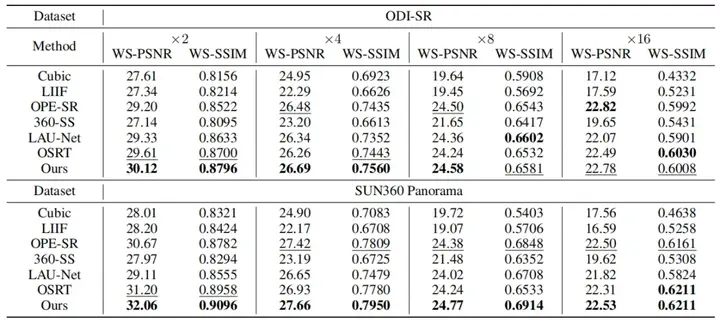
实验结果本方法在ODI-SR与SUN360全景图像测试集上的性能指标均优于已有方法。以2倍超分辨率任务为例,WS-PSNR指标分别达到30.12与32.06,WS-SSIM指标分别达到0.8796与0.9096。所提出的算法相比于最新的算法OSRT,WS-PSNR指标分别提升0.51与0.86,WS-SSIM指标分别提升0.0096与0.0138。

工作贡献
✦ 首次在全景图像超分辨中同时考虑性能和运行速度。通过专门设计的架构来捕捉球面特性并确保推理的简便性,所提出的FAOR不仅在性能上超越现有方法,还实现了显著更快的运行速度。
✦ 探索了仿射变换用于表示球面到平面的畸变,并将逐像素和语义级的球面几何先验融入全景图像潜在表示中。
✦ 提出了基于球面测地线的隐式图像函数,提供了连续且无偏的全景图像表示,促进了高效且任意尺度的全景图像超分辨过程。
论文2:
Unified Coding for Both Human Perception and Generalized Machine Analytics with CLIP Supervision
内容简介图像压缩模型长期以来一直在适应性和泛化能力方面表现乏力,因为解码后的比特流通常仅服务于人类或机器的需求,而未能为未知的视觉任务保留足够的信息。因此,本工作创新性地引入了从多模态预训练模型中获取的监督信息,并结合自适应的多目标优化方法,旨在通过单一比特流同时支持人类视觉感知和机器视觉,该方法被称为UG-ICM。
具体而言,为消除压缩模型对下游任务监督的依赖,本工作将对比语言-图像预训练模型(CLIP)引入到训练约束中,以提升模型的泛化能力。通过从全局到实例级别的CLIP监督,帮助获取分层语义,使模型能够更好地应对依赖于不同粒度信息的任务。此外,为了仅使用统一的比特流同时支持人类和机器视觉,我们引入了一种条件解码策略,该策略根据人类或机器的偏好作为条件,将比特流解码为符合相应偏好的不同版本。由此,我们提出的UG-ICM实现了完全的自监督训练,即无需了解任何具体的下游模型和任务。大量实验表明,UG-ICM在各种未知的机器分析任务中取得了显著的性能提升,同时还能生成满足人类感知要求的图像。
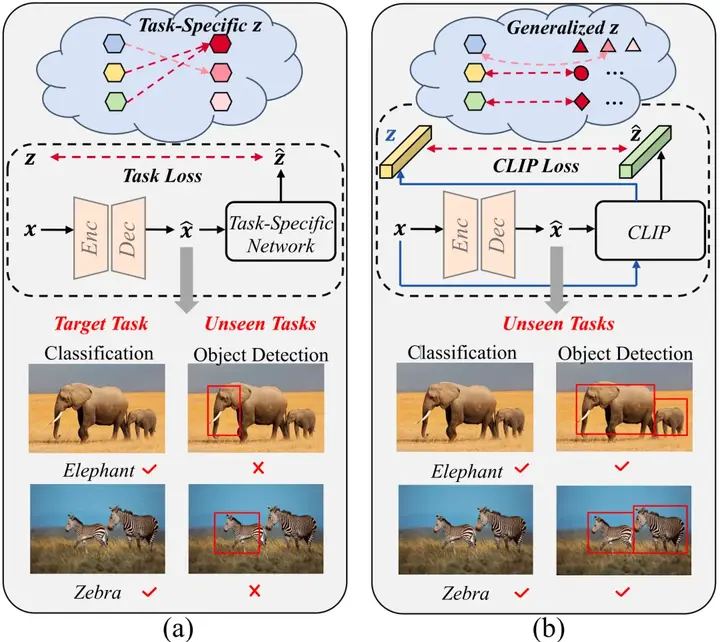

实验结果
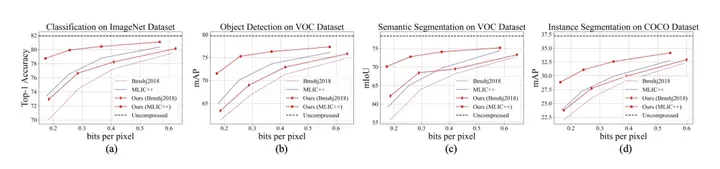
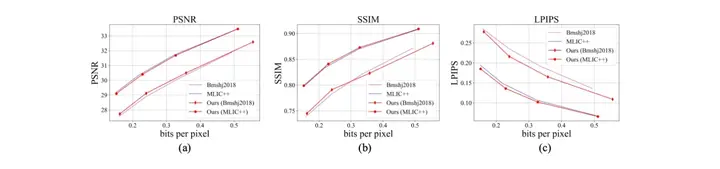
本工作在分类,目标检测,语义分割,实例分割任任务上验证了提出方法的优越性。如图3所示,在使用Bmshj主干网络的情况下,所提出的方法在相同的每像素比特数(bpp)水平下,在分类、目标检测、语义分割和实例分割任务中分别实现了平均1.7%的Top-1准确率提升、1.7%的mAP提升、3.2%的mIOU提升以及1.2%的mAP提升。而在使用MLIC++主干网络时,提升幅度更大,针对这四个下游任务,平均bpp-analytics增益分别达到2.8%、3.9%、6.0%和3.2%。考虑到下游网络及其对应的标注信息对UG-ICM完全不可见,这些提升是非常显著的,表明CLIP模型中丰富的图像模态知识已被我们的方案全面有效地利用。与此同时还极大的维持了人类感知质量,具体如4所示。
工作贡献
✦ 首次探索利用CLIP模型在面向机器的图像编码领域构建内在且通用的语义约束,以自监督方式实现强泛化能力。
✦ 提出一种统一的面向机器的图像编码范式,通过单一比特流同时提供优异的感知质量和提升的分析性能。
✦ 引入偏好条件解码模块,使单一比特流能够解码为不同版本,分别满足人类或机器的特定需求。
素材来源 丨光明实验室大数据智能处理与分析团队
编 辑 丨 李沛昱
审 核 丨 郭 锴



 发布时间:2024-12-30
发布时间:2024-12-30 作者:光明实验室
作者:光明实验室 浏览:4725次
浏览:4725次