



科研动态 | 光明实验室生成式大模型团队最新进展——GPBench:首个针对全科医生真实工作场景的大模型测评方案
![]() 发布时间:2025-03-26
发布时间:2025-03-26![]() 作者:光明实验室
作者:光明实验室![]() 浏览:2579次
浏览:2579次

当下,人工智能技术正与医疗深度融合,尤其是大语言模型 (LLMs),如DeepSeek,在医疗领域中的应用潜力引发了广泛的关注。然而,LLMs真的能胜任全科医生的工作吗?它们在诊断、治疗、健康管理等全科临床实际应用方面的表现究竟如何?
为了科学评估LLMs在全科医生工作场景中的能力,光明实验室的生成式大模型团队联合中山六院的专家医生团队,成功推出了首个针对全科真实工作场景的LLMs评估框架——GPBench,为LLMs在全科医学中的落地应用提供了科学性的测评体系。
一个新的LLMs评估框架:基于全科胜任力模型的LLMs评估
为了评估LLMs在真实医疗场景中的能力,我们借鉴全科医生的评估方法来评价LLMs。GPBench基于全科胜任力模型,构建了一个涵盖6个一级指标、16个二级指标的针对全科真实工作场景的LLM评估体系(具体参见图1),系统地评估了LLM需要具备的、全科医生日常工作中所需的主要能力点。为了全面评估LLM在全科日常诊疗中实际应用能力,GPBench构建了3个测试集:MCQ测试集,Clinical Case测试集和AI Patient 测试集。MCQ测试集主要包含QA类型的选择题,侧重测试大模型的知识能力。Clinical Case测试集主要包含临床常见的8大病种和10大症状的病例,每个病例由临床医生精细标注了正确答案和评分标准。AI Patient 测试集是利用大模型模拟得了某种疾病的病人,让待测试的大模型来问诊,主要以模拟的方式来尽可能真实地模拟医生真实工作场景。
所有测试数据均由三甲医院的专家团队精心筛选,并根据临床处置标准构建高精度的ground truth。数据经过严格的细粒度标签,涵盖核心胜任力指标,确保评测结果精准性和临床参考价值。所有数据均经过严格地脱敏处理和医学伦理审核,以确保评测的科学性和严谨性。在所有的测试集上,我们基于全科胜任力模型来评估当前的大模型。
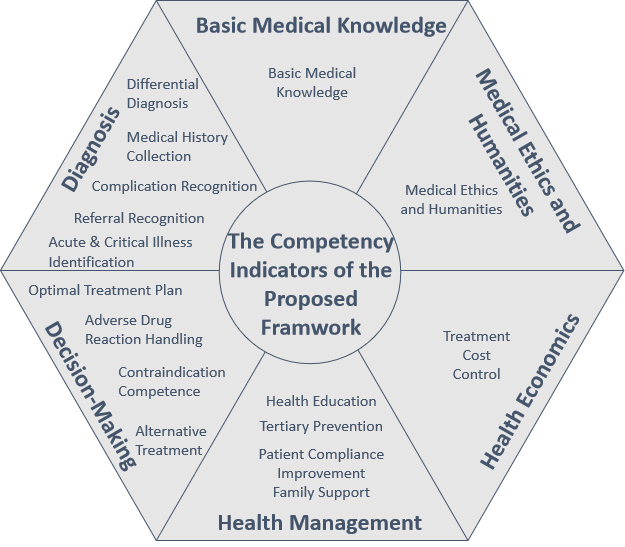
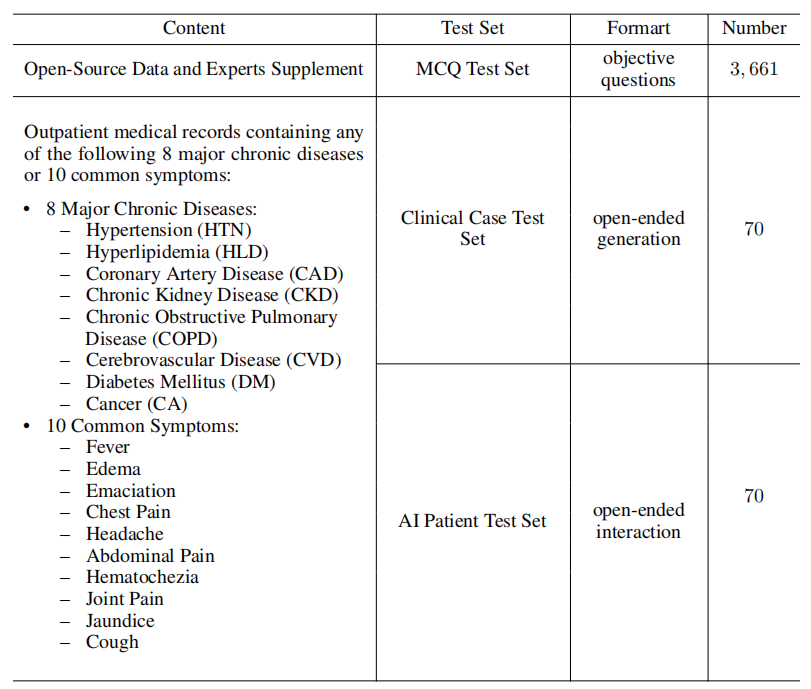
评测结果:LLMs仍存在多项能力共性短板
我们对现有主流的10个模型在GPBench上进行了评估,评估结果发现目前LLMs仍然不能满足全科医生工作的核心需求,在多个维度存在显著缺陷。值得关注的是,国产大模型DeepSeek-R1在诊断、治疗等关键能力点上相比其他LLMs表现突出,但仍与其他模型存在共性能力短板。我们测评中发现的这些共性的短板列举如下:
● 【诊断方面】LLMs普遍存在分级分期体系缺失且存在幻觉 、并发症识别盲区、急危重症判断缺失以及少见病诊断不足等问题。
● 【治疗决策】LLMs普遍存在治疗目标缺失、药物管理风险、非药物处置盲区和重症处置规范性不足等问题。
● 【健康管理】LLMs在健康教育建议中存在过度原则化的倾向,尽管其输出内容符合基本评分标准,但是停留在较为宽泛的原则性层面,缺乏具体的可操作性指导,难以有效支持临床实践需求。
● 【卫生经济学】 在开放式任务Clinical Case测试集和AI Patient 测试集的评估中,我们发现所有LLMs在涉及治疗费用控制、人文关怀等指标时,即使已经被明确提示,但仍未能主动呈现出这些能力。这说明前LLM对全科医疗服务的认知还处于简化的诊断治疗层面,缺乏对医疗服务社会属性的理解。
● 【医学伦理和人文关怀】所有LLMs在临床医疗决策领域中仍然存在过度医疗医疗倾向的风险和误诊漏诊的风险。
在测评的10个LLM中,DeepSeek-R1在诊断和治疗维度中的表现相对较好:在诊断时,对疾病的分级分期相对准确,诊断名称相比其他LLM规范和全面;在制定治疗方案时,DeepSeek-R1能够根据患者病情、用药禁忌等因素调整治疗策略,并注重用药监测。这种与其他模型的显著差异化为未来LLMs在全科医学中应用提示了优化方向。但是在AI patient测试集中,我们发现DeepSeek-R1在遵循指令方面仍有进一步的优化空间。
我们的研究证明了现有LLMs仍不适合在脱离人类监管的情况下在现实全科医生工作场景中独立部署和使用。尽管国产大模型DeepSeek-R1在多个关键能力点上表现突出,但仍与其他模型存在共性能力缺陷。目前团队已将研究整理发布,各模型的详细对比可通过项目主页 https://aiprimarycare.github.io/GPbench/ 查看。
未来计划
GPBench作为首个专注于全科胜任力评估的LLMs医学测评框架,开创性地实现了对大模型在全科医学领域的系统化评估,为医疗AI在全科诊疗中的实际应用提供了标准化范式。研究证明现有LLMs仍不能满足全科医生工作的核心能力需求。未来,光明实验室生成式大模型团队将携手中山六院,与更多科研机构及权威医疗组织深度合作,共同扩展和持续更新医疗评测数据集,推动大模型在全科医疗中的应用落地。
目前团队正在招聘大模型算法岗位实习生,有意向者可投递简历至: jiangwenhao@gml.ac.cn。
END
素材来源 丨生成式大模型团队
编 辑 丨 李沛昱
审 核 丨 杨怡莹 李沛昱 郭 锴



 发布时间:2025-03-26
发布时间:2025-03-26 作者:光明实验室
作者:光明实验室 浏览:2579次
浏览:2579次