



科研动态 | 光明实验室媒体智能团队最新进展——EmoBench-M:首个多模态大语言模型情感智能评测基准发布
![]() 发布时间:2025-03-31
发布时间:2025-03-31![]() 作者:光明实验室
作者:光明实验室![]() 浏览:3278次
浏览:3278次

光明实验室的媒体智能团队为主导,联合澳门大学、中科院自动化研究所,成功推出首个基于心理学理论的多模态大语言模型情感智能评测基准——EmoBench-M,为MLLMs的情感能力提供全面、科学的评估工具。
引言
随着多模态大语言模型(MLLMs)在机器人、虚拟助手等领域的广泛应用,如何让AI具备人类般的情感理解能力成为关键挑战。然而,现有评测标准多局限于静态文本或图像,难以反映真实场景中动态、多模态的情感表达。为此,以光明实验室的媒体智能团队为主导并联合澳门大学、中科院自动化研究所,成功推出首个基于心理学理论的多模态大语言模型情感智能评测基准——EmoBench-M,为MLLMs的情感能力提供全面、科学的评估工具。作者:He Hu, Yucheng Zhou, Lianzhong You, Hongbo Xu, Qianning Wang, Zheng Lian, Fei Richard Yu, Fei Ma, Laizhong Cui。
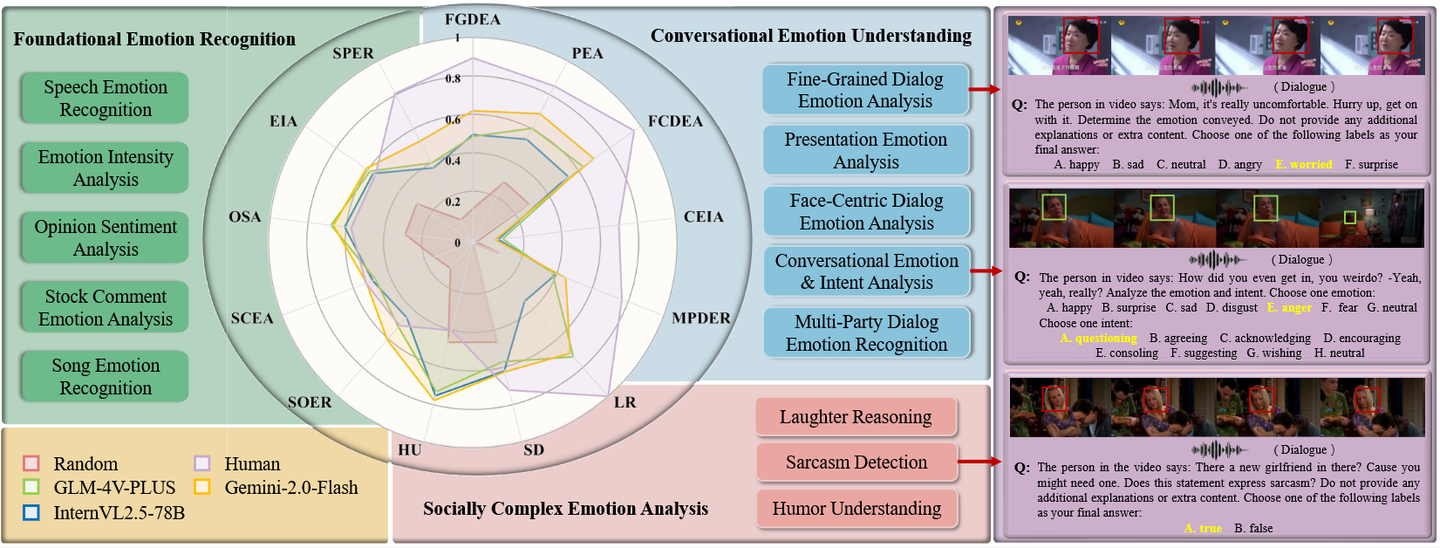
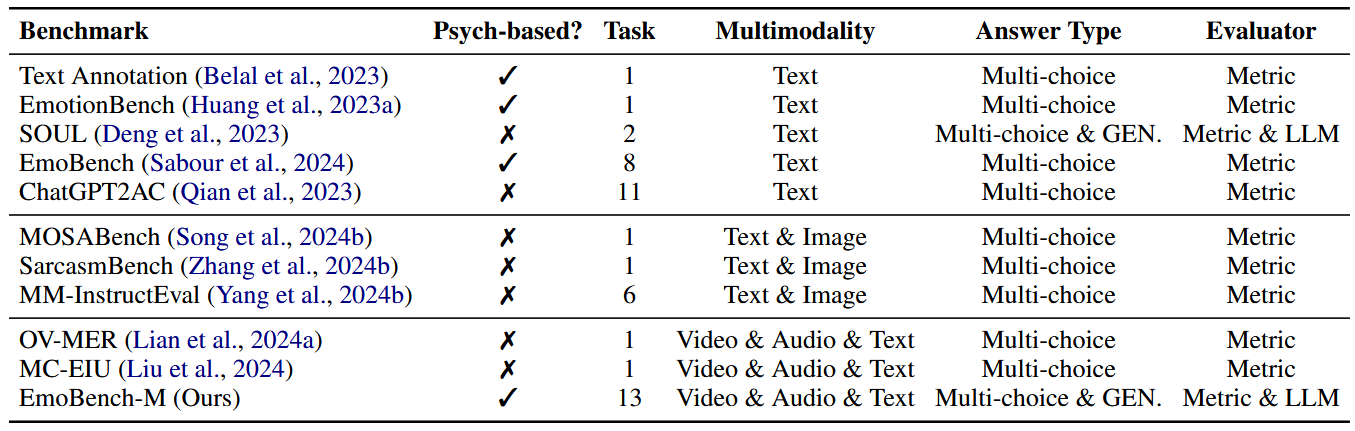
EmoBench-M基于心理学情感智能理论构建,涵盖了基础情感识别、对话情感理解和社会复杂情感分析三大核心维度,共包含13个真实世界评测场景,如音乐情绪识别、股票评论情绪分析、多方对话情绪识别、幽默和讽刺检测等。该基准首次整合视频、音频和文本多种模态数据,真实模拟了日常生活中人与人、人与机器交互过程中复杂的情绪表达,填补了现有单一模态或静态数据集在动态情感识别上的不足。
核心创新点
※全新多模态评测框架:首次引入基于视频、音频和文本的全面情感智能评估,涵盖了13种评测情境,包括歌曲情绪识别、言语情绪识别、幽默理解、讽刺检测、以及复杂的多人对话情感分析等。
※严格数据质量控制:研究团队通过多轮人工审核,去除有争议或模糊的数据,以确保评测结果的可靠性。
※明确的心理学理论支撑:评测框架参考经典的心理学情感理论,确保评测内容具有理论严谨性与实际适用性。
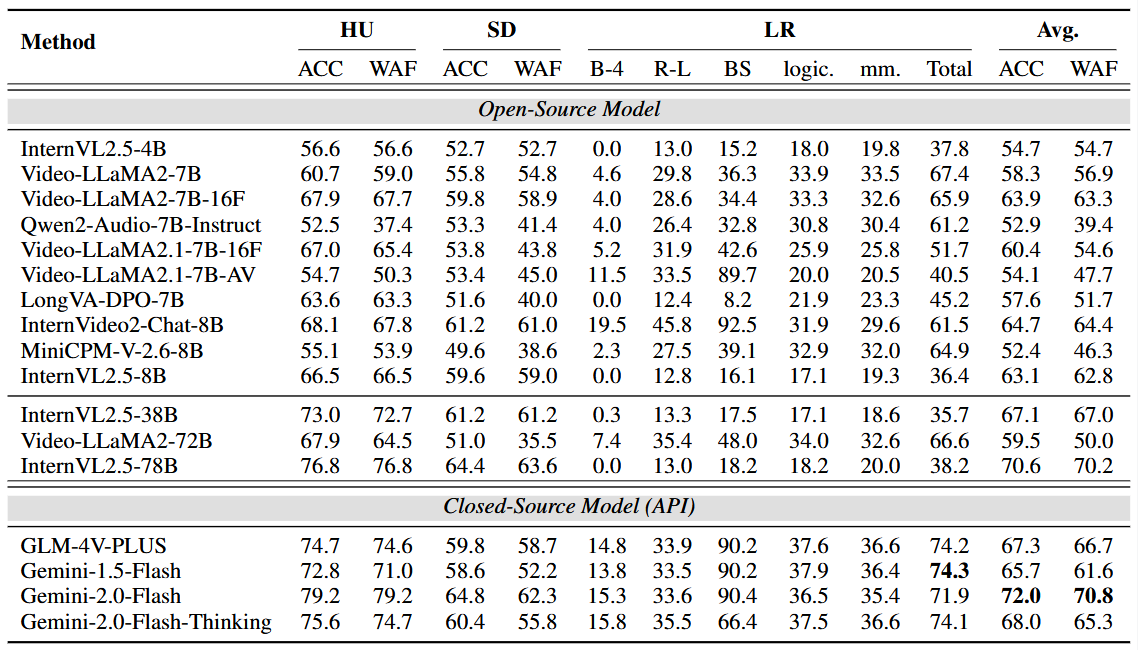
评测结果
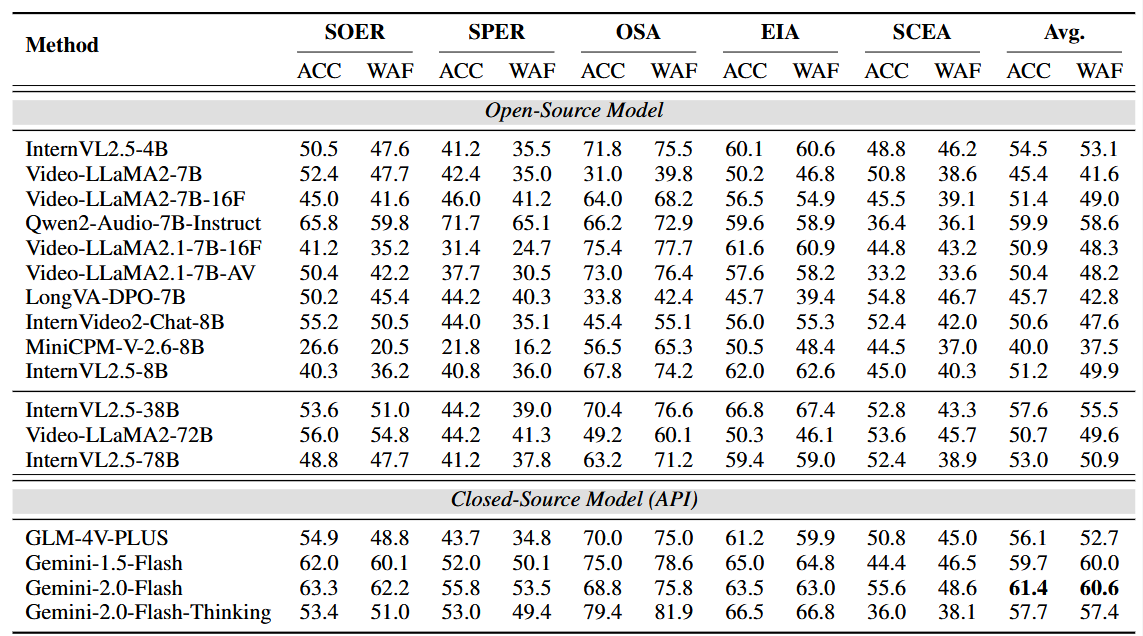
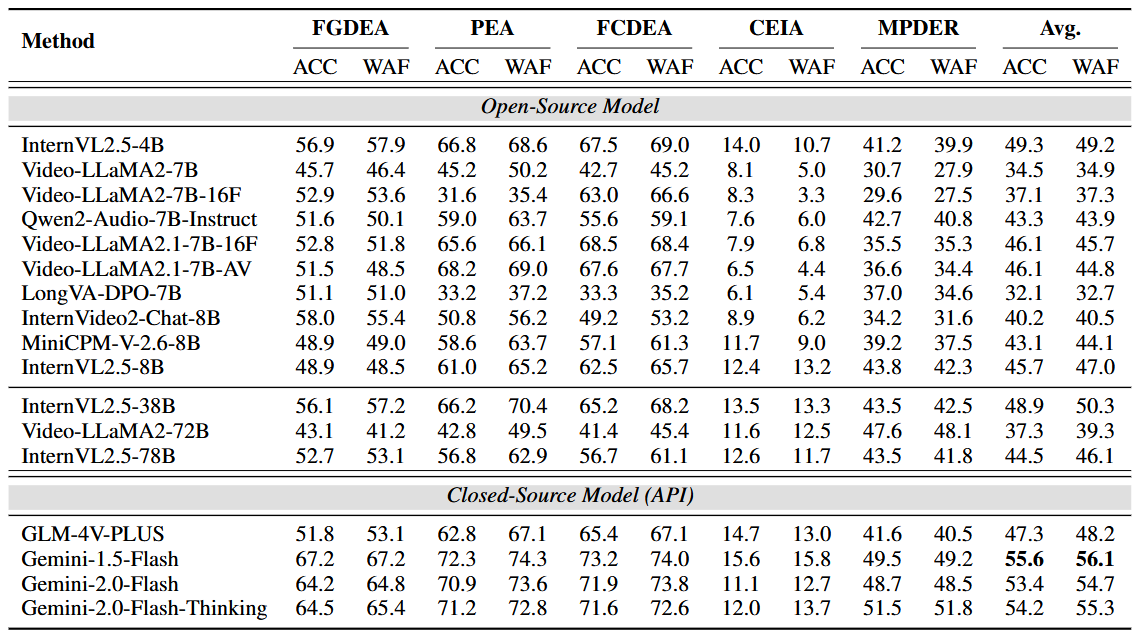
我们对当前主流的17个开源及闭源多模态大模型进行了全面评测(如InternVL、Video-LLaMA2、GLM-4V和Gemini等)进行了广泛测试,发现目前最先进的闭源模型Gemini-2.0-Flash表现相对较好,但其整体表现仍显著低于人类,尤其是在需要深度理解对话情境和社会复杂情感的任务上。尽管Gemini-2.0-Flash在基础情感识别任务中准确率可达61.4%,但在人类擅长的对话情感理解领域,其表现只有53.4%,远低于人类的84.4%。这一结果凸显出当前多模态大语言模型在处理真实、复杂情感交流时的局限性,明确了未来研究需聚焦于提升模型的社会情境理解和跨文化情感识别能力。
EmoBench-M的发布为AI情感研究提供了标准化评测工具,未来可聚焦以下方向:
1. 增强上下文建模:提升模型对动态对话和社会文化的理解能力。
2. 多模态融合优化:整合视觉、音频等信号以更精准捕捉情感。
3. 跨文化数据扩展:构建更包容的数据集以减少文化偏差。
研究团队表示,这一成果将加速情感智能技术在医疗、教育、人机交互等领域的落地应用,推动AI从“感知”向“共情”进化。未来,光明实验室媒体智能团队将继续推进情感多模态大模型与情感智能等方面的研究,以支持国产算力平台在AI情感陪伴与互动方面的发展。目前团队已将研究整理发布,各模型的详细对比可通过项目主页https://emo-gml.github.io/查看。
引用格式
@article{hu2025emobench,
title={EmoBench-M: Benchmarking Emotional Intelligence for Multimodal Large Language Models},
author={Hu, He and Zhou, Yucheng and You, Lianzhong and Xu, Hongbo and Wang, Qianning and Lian, Zheng and Yu, Fei Richard and Ma, Fei and Cui, Laizhong},
journal={arXiv preprint arXiv:2502.04424},
year={2025}
}
光明实验室媒体智能团队致力于从事(1)数字人及交互生成、(2)图片及视频的理解与生成、(3)多模态大模型与情感智能等方面的工作,长期招聘全职序列(研究员、副研究员、工程师)与研究型实习生,欢迎联系与交流:mafei@gml.ac.cn。
END
素材来源 丨光明实验室媒体智能团队
编 辑 丨 李沛昱
审 核 丨 马 飞 李沛昱 郭 锴



 发布时间:2025-03-31
发布时间:2025-03-31 作者:光明实验室
作者:光明实验室 浏览:3278次
浏览:3278次