光明实验室泛在感知与空间智能团队综述文章被中科院一区Top期刊《Information Fusion》(影响因子:14.8)录用。
近日,光明实验室泛在感知与空间智能团队综述文章“Exploring Embodied Multimodal Large Models: Development, Datasets, and Future Directions”(作者:Shoubin Chen (陈首彬), Zehao Wu, Kai Zhang , Chunyu Li , Baiyang Zhang , Fei Ma , Fei Richard Yu , Qingquan Li)被中科院一区Top期刊《Information Fusion》(影响因子:14.8)录用。这项具有重要意义的工作深入探讨了具身多模态大模型(Embodied Multimodal Large Models,EMLMs)这一快速发展的研究领域,系统梳理了关键技术进展、核心数据集以及未来研究趋势。
该成果的突破性进展,是团队在具身智能领域构建"感知-交互-决策"全栈技术体系的重要里程碑:通过自主研发的SLAM技术夯实机器人环境感知与场景理解能力,为物理世界交互提供底层支撑;同时以EMLMs为核心,聚焦多模态语义理解、动态决策与自然人机交互等上层技术攻坚,形成"环境感知-认知推理-行为生成"的完整技术闭环。目前,团队已搭建具身智能仿真验证平台,并与工业界合作推进服务机器人、无人系统等场景的技术落地,持续推动人工智能从单一模态感知向具身化、系统化方向演进。
具身多模态大模型通过整合视觉、听觉、触觉等多种感知输入,使人工智能系统能够以更接近人类的方式感知环境、理解信息并进行交互。近年来,随着多模态大模型的发展,具身智能体也有了新的突破。然而,目前尚缺乏对于多模态大模型在具身智能体的应用的综述。因此,为了填补这一空白,该综述对300篇左右研究论文进行了系统的回顾。
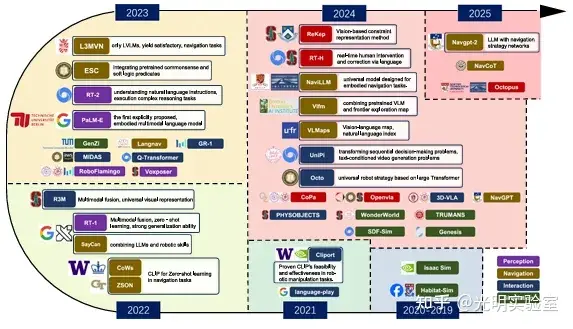
首先,该综述系统回顾了现有 EMLMs 的发展进程,详细分析了不同模态(视觉,听觉,触觉)在具身智能中的多样化应用及其所带来的优势。
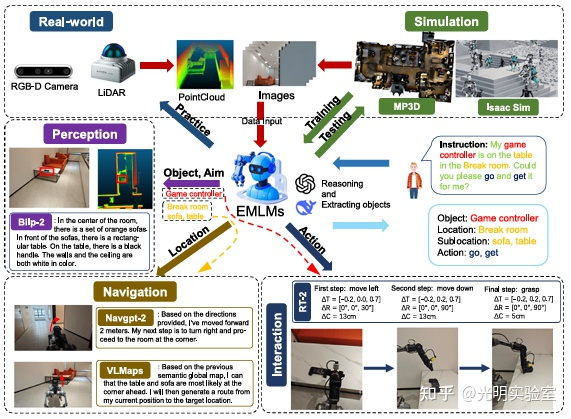
然后,文章从四个关键方面系统回顾了实现具身智能体所需的基本步骤,包括具身感知(embodied perception)、具身导航(embodied navigation)、具身交互(embodied interaction)和仿真(simulation)。这四个环节密切衔接,共同构建了具身智能体的核心能力框架,使机器人和其他智能体能够具备在复杂环境中自主感知、决策与执行任务的能力。
此外,文章强调了高质量数据集在 EMLMs 训练过程中的核心作用,分析了不同模态数据融合、模型效率与泛化性、数据收集方法以及道德与伦理问题等方面仍面临的挑战,并对未来研究方向提出了具有前瞻性的建议。
Shoubin Chen, Zehao Wu, Kai Zhang , Chunyu Li , Baiyang Zhang , Fei Ma , Fei Richard Yu, Qingquan Li. Exploring Embodied Multimodal Large Models: Development, Datasets, and Future Directions [J]. Information Fusion, 2025: 103198. https://doi.org/10.1016/j.inffus.2025.103198
素材来源 丨光明实验室泛在感知与空间智能团队
编 辑 丨 李沛昱
审 核 丨 陈首彬 李沛昱 郭 锴








 发布时间:2025-05-13
发布时间:2025-05-13 作者:光明实验室
作者:光明实验室 浏览:2108次
浏览:2108次