



光明实验室主任田奇:世界模型——初步的探索和思考
![]() 发布时间:2025-12-05
发布时间:2025-12-05![]() 作者:光明实验室
作者:光明实验室![]() 浏览:167次
浏览:167次

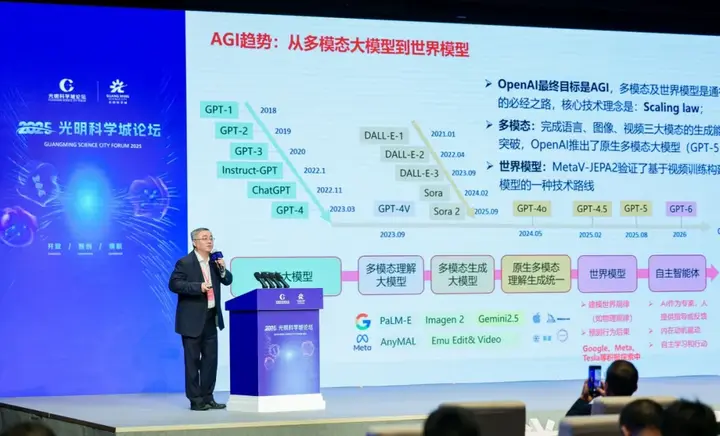
趋势前瞻 世界模型成为下一代AI探索焦点
田奇指出,当前人工智能正处于从自然语言走向多模态、再从多模态走向世界模型的阶段。AI大模型正在重塑千行百业,成为新时代人工智能的标配。AI大模型的下一步是世界模型,其作为AI发展的下一代关键方向,已成为行业前沿探索焦点。OpenAI发布的Sora、Meta的V-JEPA2、谷歌DeepMind的Genie 3等,均被视为世界模拟器的初步重要实践,但目前对世界模型的探索仍处于早期阶段,技术路径尚未形成形成统一认知。
尽管仍然面临重要挑战,世界模型仍然是一个螺旋式迭代增长的过程,从无交互环境,到专用视觉任务,再到现在4D可交互、动态生成、通用视觉任务。田奇表示,“结合终端产业需求,我们认为世界模型必须实现与物理世界的有效交互,完成从简单感知到复杂交互的跨越。”
基础突破 轻量化端侧模型与多模态编码器性能领先
在基础模型研发方面,田奇团队已实现多项重要突破:

交互攻坚 长视频理解与3D生成推动世界模型闭环构建
复杂场景交互被视为构建世界模型的核心环节。田奇表示,长视频将取代过去的图像,成为多模态理解的主要研究对象。为提升长视频语义理解的质量,田奇团队研发了三模态协同理解大模型,通过对视频进行分层标题化的数据打标,实现深度语义解析——每小时视频可生成约10万字的文字描述。为了提升搜索效率,团队在推理阶段进一步构建了三模态复杂推理大模型,通过智能信息整合显著降低搜索开销,从而在精度与速度之间取得有效平衡。
在3D技术领域,团队首创了UniLat3D预训练模型,单张图片输入、单卡3秒内即可生成高质量3D资产(加速版本可实现单卡1秒以内),研发的WorldGrow能生成可无限扩展的3D仿真环境。
“长视频理解与无限生成场景的融合,将是我们构建世界模型逻辑闭环的关键一步。”田奇说道。


本届光明科学城论坛由深圳市人民政府主办,深圳市发展改革委、市教育局、市科技创新局、市工业和信息化局、市港澳办、市外办、市科协、光明区政府、深业集团、光明科学城公司共同承办。在“光明·筑梦未来”的永久主题下,光明科学城论坛·2025以“开放”“智创”“领航”为年度主题词,汇聚行业顶尖科学家、产业领军人才与政策制定者,共同探讨前沿科技发展趋势,发布重大科技创新成果,为我国实现高水平科技自立自强贡献“光明力量”。



 发布时间:2025-12-05
发布时间:2025-12-05 作者:光明实验室
作者:光明实验室 浏览:167次
浏览:167次